
When it comes to processing, organizing, and sharing data for essential business intelligence and data prediction needs, Synapse offers a single solution for all workloads. The ability of Synapse to connect mathematical machine learning models using the ONNX standard enables its interaction with Power BI and Azure Machine Learning. Our ability to mix analytical, business intelligence, and data science solutions across services utilizing a common Data Lake is improved by Azure Synapse and Azure Databricks.
Let us understand the differences between Azure Synapse and Azure Databricks!
An Overview of Azure Synapse
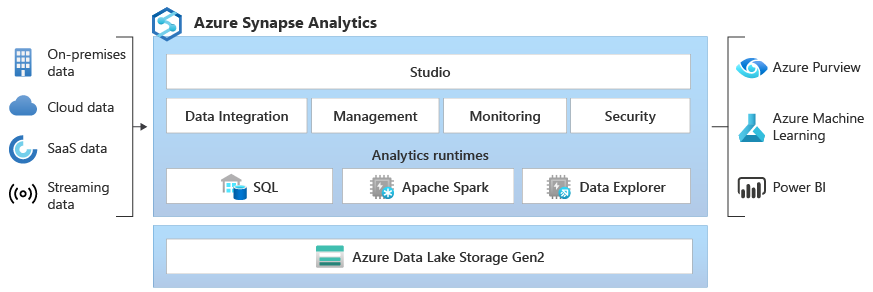
Azure Synapse Analytics is an end-to-end analytics service that enables organizations to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. It is a powerful cloud-based service that combines data warehousing and big data analytics into a single service, making it a one-stop-shop for organizations to manage their data and perform analytics.
– Industry-leading SQL
Synapse SQL is a T-SQL distributed query system that supports data warehousing and data virtualization situations while also extending T-SQL to suit streaming and machine learning applications. Serverless and dedicated resource models are available in Synapse SQL.
- Create dedicated SQL pools to reserve processing capacity for data stored in SQL tables for predictable performance and cost.
- Use the always-available, serverless SQL endpoint for unexpected or bursty workloads. Utilize the built-in streaming features to import data from cloud data sources into SQL tables.
- Integrate AI and SQL by scoring data with machine learning models using the T-SQL PREDICT function.
– Industry-standard Apache Spark
Apache Spark for Azure Synapse integrates Apache Spark, the most popular open-source big data engine used for data preparation, data engineering, ETL, and machine learning, deeply and smoothly.
- ML models for Apache Spark 2.4 featuring SparkML algorithms and AzureML integration, as well as built-in support for the Linux Foundation Delta Lake.
- Simplified resource paradigm that eliminates the need to manage clusters.
- Spark startup is quick, and autoscaling is aggressive.
- Spark includes.NET compatibility, allowing you to utilise your C# skills and existing.NET code within a Spark application.
– Working with your Data Lake
Azure Synapse lowers the usual technological obstacles to combining SQL with Spark. You can mix and combine according to your needs and skills.
- Tables defined on files in the data lake are consumed in real time by Spark or Hive.
- SQL and Spark can natively explore and analyse data lake files such as Parquet, CSV, TSV, and JSON.
- Data loading between SQL and Spark databases is quick and scalable.
– Built-in data integration
Azure Synapse Analytics includes the same Data Integration engine and experiences as Azure Data Factory, allowing you to build sophisticated at-scale ETL pipelines without leaving Azure Synapse Analytics.
- Data from more than 90 data sources is ingested.
- Data flow operations with code-free ETL
- Notebooks, Spark jobs, stored procedures, SQL scripts, and other resources may be orchestrated.

How does Azure Synapse Analytics work?
The primary purpose of Azure Synapse Analytics is to help organizations make sense of their data by providing a seamless and unified experience that empowers them to easily perform analytics on large data sets. The service provides a variety of tools and features that enable organizations to do the following:
- Ingest data: Azure Synapse Analytics enables organizations to easily ingest data from various sources, including structured, semi-structured, and unstructured data sources. It supports a range of ingestion methods, including batch, streaming, and event-based ingestion.
- Prepare data: Once the data is ingested, Azure Synapse Analytics provides a range of data preparation tools that enable organizations to clean, transform, and enrich the data. These tools include data wrangling, data flow, and data transformation capabilities.
- Manage data: Azure Synapse Analytics provides a range of data management tools that enable organizations to easily manage their data at scale. This includes data governance, security, and compliance features, as well as data cataloging and data lineage capabilities.
- Perform analytics: Azure Synapse Analytics provides a range of analytics tools that enable organizations to perform business intelligence and machine learning tasks on their data. This includes SQL-based analytics using Azure Synapse SQL, big data analytics using Apache Spark, and machine learning using Azure Machine Learning.
- Serve data: Finally, Azure Synapse Analytics provides a range of data serving capabilities that enable organizations to easily serve their data to various applications and users. This includes serving data through Power BI, Azure Data Factory, and other Azure services.
Azure Data Lake Storage is used by Azure Synapse. Gen2 is both a data warehouse and a unified data model. Administration, monitoring, and metadata management are all covered. In terms of security, it allows you to protect, monitor, and manage your data and analytic solutions, for example, by using a single sign-on and an Azure Active Directory connection. Azure Synapse, in essence, completes the whole data integration and ETL process and is far more than a standard data warehouse since it includes additional stages of the process that allow users to create reports and visualisations.
It supports a variety of programming languages, including SQL, Python,.NET, Java, Scala, and R. As a result, it is well suited to various analysis workloads and engineering profiles. Everything is included in the Synapse Analytics Studio, which makes it simple to combine Artificial Intelligence, Machine Learning; IoT, intelligent apps and business intelligence all on the same unified platform.
An Overview of Azure Databricks
Azure Databricks is a collaborative and scalable analytics platform that enables data engineering, data science, and machine learning workloads on the cloud. It is a powerful cloud-based service that provides a unified workspace for data engineering, data science, and machine learning tasks, making it easier for organizations to collaborate and scale their analytics workloads.
Databricks in SQL is a simple platform for analysts who wish to perform SQL queries on their data lake, generate several visualisation types to analyse query results from various angles, and build and share dashboards.
Additionally, Databricks in Data Science & Engineering provides an interactive platform for data engineers, data scientists, and machine learning engineers to collaborate. In a large data pipeline, data (raw or structured) is imported into Azure in batches through Azure Data Factory or streamed in near real-time via Apache Kafka, Event Hub, or IoT Hub. This data is store in a data lake for long-term retention, either in Azure Blob Storage or Azure Data Lake Storage. Use Azure Databricks as part of your analytics process to read data from different data sources and transform it into breakthrough insights using Spark.
Databricks in Machine Learning is a complete machine learning environment that includes managed services for experiment tracking, model training, feature development and administration, and feature and model serving.
Launch an Azure Databricks workspace and use the persona switcher in the sidebar to pick an environment:
Purpose of Azure Databricks:
The primary purpose of Azure Databricks is to provide a collaborative platform for data scientists, data engineers, and business analysts to work together on data analytics projects. The platform provides a range of tools and features that enable organizations to do the following:
- Data Engineering: Azure Databricks provides a range of data engineering tools that enable organizations to easily process and prepare their data for analysis. This includes support for Apache Spark, which allows organizations to perform data processing tasks at scale.
- Data Science: Azure Databricks provides a range of tools for data scientists, including support for popular programming languages like Python, R, and Scala, as well as support for popular data science libraries like Pandas and Scikit-learn. Data scientists can use these tools to perform advanced analytics tasks such as machine learning, deep learning, and natural language processing.
- Machine Learning: Azure Databricks provides a range of tools for machine learning, including support for popular machine learning libraries like TensorFlow, PyTorch, and Spark ML. The platform also provides tools for model training, hyperparameter tuning, and model deployment.
- Collaboration: Azure Databricks provides a unified workspace for collaboration, allowing data scientists, data engineers, and business analysts to work together on the same data analytics project. The platform provides tools for version control, code review, and collaboration, making it easier for teams to work together and achieve their data analytics goals.
- Scalability: Azure Databricks is a scalable platform that can handle large volumes of data and perform data processing tasks at scale. The platform provides automatic scaling of compute resources, enabling organizations to scale up or down based on their analytics needs.
How is Azure Synapse different from Azure Databricks?
The following ways will help you understand the differences better –
– On the Road to Maximum Compatibility and Power
The Microsoft service was initially pitched as a solution to two basic difficulties that businesses must face. Compatibility is the first of these. It includes a data analysis system that can deal with both standard systems and unstructured data, as well as a variety of data sources. It can therefore evaluate data contained in systems (customer databases) as well as data in a Data Lake in parquet format.
However, it also enables greater adaptability in automatically managing activities to develop a data analysis system. This improved power has the immediate effect of decreasing the amount of labour required by programmers. As a result, project development timelines (it is the first and only analysis system that has executed all TPC-H queries at petabyte-scale).
Azure Synapse allows projects that would normally take months to be finished in days. And sophisticated database queries that would normally take minutes or hours to get executed in a matter of seconds.
– Successful consultations in milliseconds
Aside from the flexibility to scale processes and storage resources individually; Azure Synapse Analytics is notable for its result caching feature (it has a fully managed 1 TB cache). As a result, when a query is made, it is cached in order to speed up the following query that consumes the same type of data. This is one of the secrets of its ability to respond in milliseconds. This is due to the cache’s ability to withstand pause, resume, and scale operations; (which can be activated very quickly by a massively parallel processing architecture designed for the cloud).
– Workloads and Performance
Its comprehensive support for JSON, data masking provides high levels of security. Additionally, SSDT (SQL Server Data Tools) compatibility and notably workload management and how it may improve and segregated are also noteworthy. Multiple workloads share implemented resources in this case. This enables the creation of a task and the assignment of CPU and concurrency to it.
In terms of data preparation and ingestion it offers integrated streaming (Native SQL Streaming) to perform analytics; such as through integration with an Event Hub or an IoT Hub. And it does so by providing high speed of up to 200MB/second; delivery latencies in seconds, ingest performance that grows with computing size; and analytical capabilities via Microsoft SQL-based queries for combinations, aggregations, filters, and so on.
In the instance of 1000 DWU (Data Warehouse Units), Azure Synapse streamlines the process of allocating a proportion of labour to sales; and another to marketing (for example 60 percent to one and 40 percent to the other). The goal is to make administration easier and to prioritise database requests.
Additional features
Finally, we can’t leave Azure Synapse Analytics without mentioning some more fascinating features that assist speed up data loading and simplify procedures. Among them are the following:
- The Copy order eliminates the need for external tables for data preparation; and loading by allowing you to import tables directly into the database.
- It fully supports conventional CSV, including line breaks, custom delimiters, and SQL dates.
- Allows for user-controlled file selection (wildcard support)
- Machine Learning models may be developed and saved in ONNX format, which then storea in the Azure Synapse data storage; and utilised with the native PREDICT command.
- Integration with Data Lake: Files are read in the Data Lake in Parquet format from Azure Synapse; achieving a considerably greater speed and boosting Polybase execution by over 13x.
Quick Comparison: Azure Databricks and Azure Synapse
Azure Synapse Analytics and Azure Databricks are both powerful data analytics services offered by Microsoft Azure. Here are some key differences between the two:
- Purpose: Azure Synapse Analytics is designed to be an end-to-end analytics service that allows organizations to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. Azure Databricks, on the other hand, is a cloud-based analytics service that is designed to provide a collaborative and scalable platform for data engineering, data science, and machine learning workloads.
- Data Processing Capabilities: Azure Synapse Analytics provides a range of data processing capabilities such as data warehousing, big data analytics, and data integration. Azure Databricks is more focused on data engineering and machine learning workloads, offering a powerful Apache Spark-based analytics platform that allows for scalable data processing, data exploration, and machine learning model training.
- User Interface: Azure Synapse Analytics provides a unified workspace that includes data warehousing, data integration, and big data analytics in a single user interface. Azure Databricks, on the other hand, provides a collaborative workspace that is optimized for Apache Spark-based data processing and machine learning workloads.
- Integration with other Azure Services: Both services are integrated with other Azure services, but Azure Synapse Analytics is more tightly integrated with other Azure services such as Azure Machine Learning, Azure Data Factory, and Azure Stream Analytics.
- Cost: Azure Synapse Analytics is priced based on the amount of data processed, while Azure Databricks is priced based on the amount of compute resources used. This means that the cost of using these services can vary significantly depending on the specific workload and data processing requirements.
Expert Corner
Azure Databricks is now up and running, with improvements to the spark engine, cross-platform support, and a mature workspace. Nonetheless, Azure Synapse Analytics functions as a primary integrated platform. Azure announced the renaming of Azure SQL Data Warehouse as Azure Synapse Analytics.
But this was not a different name for the same service. Azure Synapse now includes a slew of new features designed to bridge the gap between big data. And data warehousing solutions. In a nutshell, a service that ensures SQL DW users may continue to run existing data storage workloads in production while automatically benefiting from new capabilities.
