
Amazon SageMaker is a fully managed assistance that allows data scientists and developers to instantly and easily formulate, train, and expand machine learning patterns at any scale. Amazon SageMaker comprises modules that can be practiced together or separately to build, train, and deploy the machine learning prototypes. It implements a multicultural Jupyter authoring notebook instance for secure access to the data sources for research and analysis. Also, it presents traditional machine learning algorithms that are optimized to work efficiently against remarkably large data in a distributed environment.
Components of Amazon SageMaker:
1. Learn to Build
- Amazon SageMaker makes it simple to create ML models and get them available for training by giving everything one needs to instantly relate to the training data and to choose and optimize the most suitable algorithm and framework for the application.
- Further, Amazon SageMaker incorporates hosted Jupyter notebooks that perform it is straightforward to explore and reflect the training data collected in Amazon S3.
- To encourage you to choose your algorithm, Amazon SageMaker comprises the 10 most popular machine learning algorithms which have been pre-installed and optimized to liberate up to 10 times the production you’ll find working these algorithms anywhere else.
2. Learn to Train
- One can begin training the model with a single click in the Amazon SageMaker console. Amazon SageMaker manages all of the underlying frameworks and can scale to train models at a petabyte-scale.
- Secondly, to make the training process even more active and more sincere, AmazonSageMaker can automatically adapt the model to achieve the greatest possible performance.
3. Learn to Deploy
- After preparing the model, Amazon SageMaker makes it simple to expand in production so one can begin working generating prognostications on new data (a process designated as inference).
- Amazon SageMaker extends the model on an auto-scaling group of Amazon EC2 instances that are scattered across various availability zones to achieve both high production and high availability.
- Amazon SageMaker incorporates built-in A/B testing abilities to help one to test their model and experiment with various versions to obtain the best results.
Features of SageMaker:
Some of the top features of Amazon SageMaker are:
1. Preparing Data in Minutes
- You can quickly and simply prepare data and develop model features using Amazon SageMaker Data Wrangler. Further, to engineer model features, you may connect to data sources and use built-in data transformations.
2. Transparency
- The data in Amazon SageMaker Clarify is for improving model quality by detecting bias during data preparation and after training. Moreover, model explainability reports are also provided by SageMaker Clarify, allowing stakeholders to see how and why models produce predictions.
3. Security and Privacy
- From the start, Amazon SageMaker gives you access to a completely secure machine learning environment. You can support a wide range of industry laws with a complete set of security features.
4. Data Labeling
- Amazon SageMaker Ground Truth makes it simple to create extremely accurate machine learning training datasets. Further, use the SageMaker Ground Truth dashboard to label your data in minutes, utilizing customs or built-in data labeling workflows such as 3D point clouds, video, pictures, and text.
5. Feature Store
- The Amazon SageMaker Feature Store is a dedicated feature store for machine learning (ML) supplying features in real-time and batch. You can save, find, and exchange features securely so that you obtain the same features throughout training and inference, saving months of development time.
6. Data Processing at Scale
- Amazon SageMaker Processing expands SageMaker’s convenience, scalability, and dependability to data processing tasks in the cloud. SageMaker Processing connects to existing storage, spins up the resources needed to perform your task, saves the output to permanent storage, and logs and analytics.
7. One-click Jupyter Notebooks
- Amazon SageMaker Studio Notebooks are one-click Jupyter notebooks with completely elastic computing resources, allowing you to simply scale up or down the number of resources available. Notebooks can shared with a simple click, ensuring that colleagues have access to the same notebook at the same location.
8. Built-in Algorithms
- Over 15 built-in algorithms are available in pre-built container images in Amazon SageMaker, which may be used to quickly train and perform inference.
9. Pre-Built Solutions and Open-Source Models
- Amazon SageMaker JumpStart enables you to get started with machine learning rapidly with pre-built solutions that can be deployed in a matter of minutes. More than 150 popular open-source models may be deployed and fine-tuned with one click using SageMaker JumpStart.
10. AutoML
- Amazon SageMaker Autopilot creates, trains, and tunes the finest machine learning models based on your data while giving you complete control and visibility. The model may then be deployed to production with a single click, or you can iterate to increase the model’s quality.
11. Optimized for Major Frameworks
- Many prominent deep learning frameworks, including TensorFlow, Apache MXNet, PyTorch, and others, are optimized for Amazon SageMaker. Frameworks gets continually updated to the most recent version and are tuned for AWS performance. These frameworks do not require manual setup and may be used within the built-in containers.
12. Reinforcement Learning
- In addition to typical supervised and unsupervised learning, Amazon SageMaker includes reinforcement learning. SageMaker offers built-in, fully-managed reinforcement learning algorithms, including some of the most cutting-edge and high-performing algorithms in the academic literature.
13. Managed Spot Training
- Amazon SageMaker offers Managed Spot Training, which may help you save up to 90% on training expenditures. When computing capacity becomes available, training jobs automatically executes, and they are made robust to disruptions caused by capacity fluctuations.
14. Distributed Training
- Distributed training is made easier using Amazon SageMaker. That is to say, SageMaker aids in the distribution of data over several GPUs, resulting in near-linear scaling efficiency. SageMaker also makes it easy to spread your model over many GPUs by automatically profiling and splitting your model with only a few lines of code.
15. Human review
- To verify that low confidence forecasts are true, many machine learning applications require humans to check them. For popular machine learning use cases, Amazon Augmented AI has built-in human review methods.
16. Integration with Kubernetes
- You can use Amazon SageMaker to orchestrate and manage pipelines while also using Kubernetes and Kubeflow. SageMaker allows you utilise Kubernetes operators to train and deploy models in SageMaker, and SageMaker Components for Kubeflow Pipelines lets you use SageMaker without having to manage Kubernetes for machine learning.
Is Amazon SageMaker Good?
Amazon SageMaker is very good for ML. It reaches out from the masses because it makes ML less expensive, short laborious, and less time-exhausting. Typically, the machine learning method without tools like SageMaker is dull and complex. The practitioner has to try all the tasks below:
- Collecting and preparing the training data for making ML models.
- Recognizing the ideal algorithm to train the models.
- Employing costly computers to train models for predictions
- Adjust and fine-tune models to enhance prediction accuracy.
- Incorporate trained ML models into business applications
But how to begin with building, training, and deploying a machine learning model? To get an answer for this, in the next section, we will use Amazon SageMaker for creating, training, and deploying a machine learning (ML) model.
Beginning with Amazon SageMaker
Step 1: Creating an SageMaker notebook instance for data preparation
Here, we will build the notebook instance that you’ll use to download and process your data in this stage. And, we will also build an Identity and Access Management (IAM) role that allows Amazon SageMaker to access data in Amazon S3 as part of the setup procedure.
- Firstly, sign in to the Amazon SageMaker interface and choose your desired AWS Region in the upper right corner.
- Secondly, choose Notebook instances from the left navigation window, then Create notebook instance.
- Thirdly, fill in the following fields in the Notebook instance configuration box on the Create notebook instance page:
- Type SageMaker-Tutorial for Notebook instance name.
- Select ml.t2.medium for Notebook instance type.
- Keep the default selection of none for Elastic inference.
- Then, choose to create a new role in the Permissions and encryption section for the IAM role, then in the Create an IAM role dialogue box, pick Any S3 bucket and Create role.
- Lastly, for the remaining parameters, leave the defaults alone and choose to Create a notebook instance.
- The new SageMaker-Tutorial notebook instance is listed in the Notebook instances section with a Status of Pending. When the Status switches to InService, the notebook is ready.
Step 2. Preparing the data
In this, we will use the Amazon SageMaker notebook instance to preprocess the data you’ll need to train your machine learning model, then upload it to Amazon S3.
- Firstly, choose Open Jupyter once the state of your SageMaker-Tutorial notebook instance switches to InService.
- Secondly, choose New in Jupyter, and then conda python3.
- Copy and paste the following code into a new code cell in your Jupyter notebook, then pick Run.
- This code imports the necessary libraries and sets the environment variables needed to prepare the data, train the machine learning model, and deploy the machine learning model.

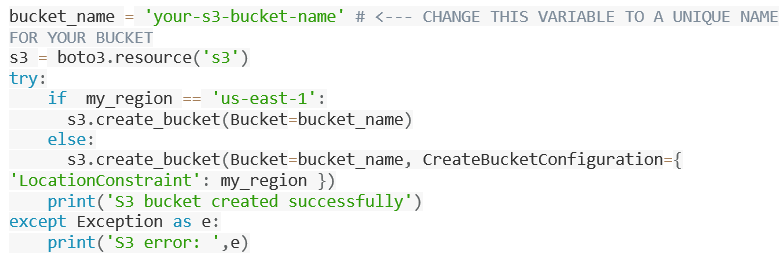
- Thirdly, to save your data, create an S3 bucket. Choose Run after copying and pasting the following code into the next code box.
- After that, load the data into a dataframe after downloading it to your SageMaker instance. Choose Run after copying and pasting the following code into the next code box.
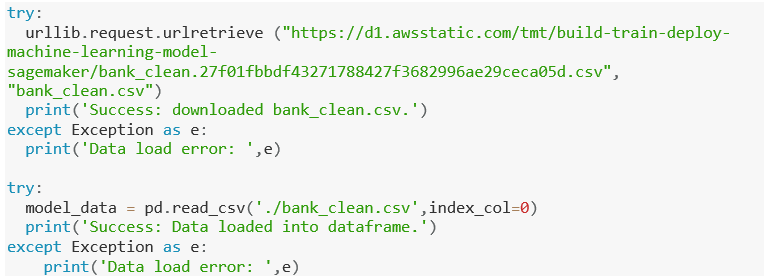
- Lastly, shuffle the data and divide it into training and test groups. Choose Run after copying and pasting the following code into the next code box.
- During the model training loop, the training data (70 percent of consumers) get employed. To iteratively adjust the model parameters, you employ gradient-based optimization. Gradient-based optimization uses the gradient of the model loss function to discover model parameter values that minimise the model error.

Step 3: Training the ML model
We’ll utilize the training dataset to train your machine learning model in this stage.
- Firstly, copy and paste the following code into a new code cell in your Jupyter notebook, then pick Run.
- However, this code reformats the training data’s header and first column before loading it from an S3 bucket. To utilize the Amazon SageMaker pre-built XGBoost algorithm, you must complete this step.

- Secondly, create an instance of the XGBoost model (an estimator) and define the model’s hyperparameters in the Amazon SageMaker session. Choose Run after copying and pasting the following code into the next code box.

- Now, choose Run after copying and pasting the following code into the next code box.
- On an ml.m4.xlarge instance, this code uses gradient optimization to train the model. In your Jupyter notebook, you should notice the training logs created within a few minutes.

Step 4: Deploying the model
In this step, we’ll upload the trained model to an endpoint, reformat and load the CSV data, and then execute the model to generate predictions in this phase.
- Firstly, copy and paste the following code into a new code cell in your Jupyter notebook, then pick Run.
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')
- However, this code uploads the model to the server and provides a SageMaker API for you to use. It’s possible that this step will take a few minutes to finish.
- Secondly, copy the following code into the next code box and pick Run to forecast whether clients in the test data subscribed for the bank product or not.
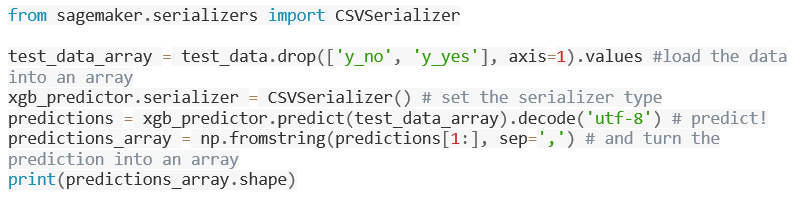
Step 5: Evaluating model performance
We’ll assess the machine learning model’s performance and accuracy in this stage.
- Copy and paste the following code into a new code cell in your Jupyter notebook, then pick Run.
- However, in a table called a confusion matrix, this code compares the actual vs. projected values.

Step 6: Cleaning up
The resources you utilized in this lab are terminated at this phase.
- Delete the following endpoint: Copy and paste the following code into your Jupyter notebook, then hit Run.
xgb_predictor.delete_endpoint(delete_endpoint_config=True)
- Deleting your S3 bucket and training artefacts: Copy and paste the following code into your Jupyter notebook, then hit Run.
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()
- Delete your SageMaker Notebook: Close your SageMaker Notebook and delete it.
- Firstly, open the SageMaker console.
- Secondly, select Notebook instances from the Notebooks menu.
- Now, choose Actions, Stop, and then choose the notebook instance you created for this lesson. Stopping the notebook instance might take several minutes. Proceed to the next step when Status changes to Stopped.
- Then, select Actions and then Delete.
Amazon SageMaker Training Costs:
- Developing machine learning models is not a cheap endeavor. It requires high-quality data to train models, which is complex, time-intensive, and expensive. Consequently, any opportunity to reduce these costs is welcomed.
- SageMaker provides several cost reduction opportunities. Firstly, SageMaker cuts data labeling costs by up to 70% using Amazon SageMaker Ground Truth. Good machine learning models require large volumes of quality training data. While creating training data is often expensive, complicated, and time-consuming, Amazon SageMaker Ground Truth helps create and manage accurate training datasets.
- Secondly, SageMaker lowers training costs by 90% using Managed Spot Training. Third, Amazon Elastic Inference decreases machine learning inference costs by 75%. It does this by aligning trained models with the right-sized instance.
