
Amazon Kinesis Data Streams (KDS) is a real-time data streaming solution that is enormously scalable and long-lasting. KDS can collect gigabytes of data per second from tens of thousands of sources, including website clickstreams, database event streams, financial transactions, social media feeds, IT logs, and location-tracking events. Real-time dashboards, real-time anomaly detection, dynamic pricing, and other real-time analytics use cases are possible thanks to the data acquired in milliseconds.
AWS Kinesis Data Streams is a managed service provided by Amazon Web Services (AWS) for real-time processing of streaming data at scale. It allows you to collect, process, and analyze large amounts of data in real-time, making it an ideal solution for use cases such as:
- Log and Metrics Collection: Kinesis Data Streams can be used to collect logs and metrics from a variety of sources, including applications, servers, and IoT devices.
- Stream Processing: Kinesis Data Streams can be used to process and analyze data in real-time, using tools such as Apache Flink, Apache Spark Streaming, and AWS Lambda.
- Analytics and Business Intelligence: Kinesis Data Streams can be used to support real-time analytics and business intelligence, providing real-time insights into business operations and customer behavior.
- Fraud Detection: Kinesis Data Streams can be used to detect and prevent fraud in real-time by analyzing large amounts of data from multiple sources.
A typical Kinesis Data Streams application reads records of data from a data stream. The Kinesis Client Library may be used by these applications, which may run on Amazon EC2 instances. You can move data to a variety of different Amazon services and use the processed information to build dashboards, send out warnings, dynamically change pricing and advertising strategies, and more.
How AWS Kinesis Data Streams Works?
AWS Kinesis Data Streams works by collecting, storing, and processing large amounts of data in real time. Here is a high-level overview of how it works:
- Data Ingestion: Data is ingested into Kinesis Data Streams from a variety of sources, such as applications, servers, and IoT devices. This data is stored in one or more shards, which are units of data storage in Kinesis Data Streams.
- Real-time Processing: Once data is stored in the shards, it can be processed in real-time using Kinesis Data Streams’ built-in processing capabilities or using tools such as Apache Flink, Apache Spark Streaming, and AWS Lambda.
- Data Analysis: The processed data can be analyzed using tools such as Amazon Redshift, Amazon QuickSight, and Amazon Athena to provide real-time insights into business operations and customer behavior.
- Data Storage: The processed data can be stored in a variety of destinations, such as Amazon S3, Amazon DynamoDB, or Amazon Elasticsearch Service.
- Scaling: Kinesis Data Streams is designed to scale automatically and handle very large amounts of data, making it easy to process and analyze large data sets in real-time.
- Monitoring: Kinesis Data Streams provides monitoring and visibility into the data processing pipeline, allowing you to monitor the data processing and identify any issues that may arise.

Kinesis Data Streams High-Level Architecture:
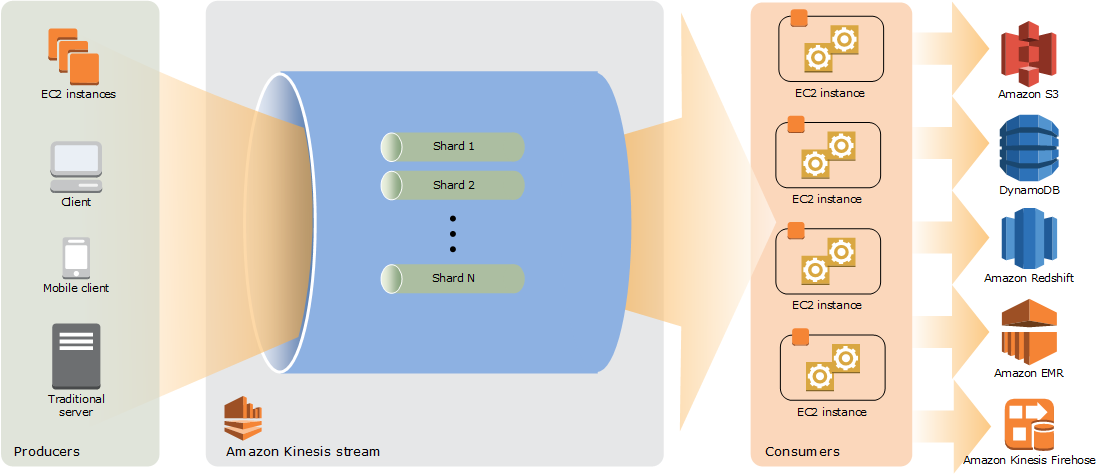
The high-level architecture of Kinesis Data Streams depicts in the diagram below. Producers provide data to Kinesis Data Streams on a regular basis, and consumers process it in real-time. Consumers (such as a custom application running on Amazon EC2 or an Amazon Kinesis Data Firehose delivery stream) can use AWS services like Amazon DynamoDB, Amazon Redshift, or Amazon S3 to store their findings.
Where do you use Amazon Kinesis Data Streams?
Real-time data collection and aggregation are possible using Kinesis Data Streams. Examples of the various types of information that may be used include data from IT infrastructure logs, application logs, social media, market data feeds, and internet clickstream data. Processing is frequently low since real-time data input and processing are both used.
Where to use Kinesis Data Streams?
The following are typical scenarios for using Kinesis Data Streams:
- Accelerated log and data feed intake and processing
- Data can immediately sent into a stream by producers. Push system and application logs, for example, and they’re ready for analysis in seconds. If the front end or application server dies, the log data is not lost. Because you don’t batch the data on the servers before submitting it for intake, Kinesis Data Streams allows for faster data feed intake.
- Real-time metrics and reporting
- Data via Kinesis Data Streams is for real-time data analysis and reporting. Rather than waiting for batches of data to arrive, your data-processing application may work on metrics and reporting for system and application logs as they come in.
- Real-time data analytics
- The strength of parallel processing get combines with the value of real-time data in this way. Process real-time website clickstreams and then measure site usability engagement utilising many Kinesis Data Streams apps operating in parallel, for example.
- Complex stream processing
- Kinesis Data Streams apps and data streams can turn into Directed Acyclic Graphs (DAGs). This usually entails combining data from numerous Kinesis Data Streams apps into a single stream for processing by another Kinesis Data Streams application later.
What are the benefits of Using Amazon Kinesis Data Streams?
Amazon Kinesis Data Streams provides several benefits for businesses looking to process and analyze large amounts of real-time data:
- Real-time Processing: Kinesis Data Streams allows you to process data in real-time, providing real-time insights into business operations and customer behavior.
- Scalability: Kinesis Data Streams is designed to handle very large amounts of data, making it easy to scale your data processing capabilities as your business grows.
- Cost-effective: Kinesis Data Streams is a cost-effective solution for real-time data processing, providing a pay-as-you-go model that eliminates the need for upfront investments in hardware and software.
- Integration with other AWS services: Kinesis Data Streams integrates seamlessly with other AWS services, such as Amazon S3, Amazon Redshift, and Amazon QuickSight, making it easy to process and analyze data.
- Flexibility: Kinesis Data Streams is a flexible solution, allowing you to choose the tools and technologies that best meet your needs for real-time data processing and analysis.
- Monitoring and Visibility: Kinesis Data Streams provides monitoring and visibility into the data processing pipeline, allowing you to monitor the data processing and identify any issues that may arise.
Overall, Amazon Kinesis Data Streams provides businesses with the ability to process and analyze large amounts of real-time data in a cost-effective, scalable, and flexible manner, providing valuable insights into business operations and customer behavior.
Important Kinesis Data Streams Terminology
1. Kinesis Data Stream
A group of shards makes up a Kinesis data stream. A succession of data records exists in each shard. Kinesis Data Streams gives a sequence number to each data record.
2. Data Record
A data record is the smallest unit of data in a Kinesis data stream. A data record is made up of a sequence number, a partition key, and an immutable series of bytes called a data blob. Kinesis Data Streams does not examine, analyze, or modify the data in the blob in any way. A data blob can be as big as 1 megabyte.
3. Retention Period
The retention period refers to how long data records can access once introducing in the stream. The default retention duration for a stream is 24 hours after creation. The IncreaseStreamRetentionPeriod operation may extend the retention duration up to 8760 hours (365 days), while the DecreaseStreamRetentionPeriod operation can reduce the retention period to a minimum of 24 hours. Streams having a retention length of greater than 24 hours are subject to additional fees. See Amazon Kinesis Data Streams Pricing for further details.
4. Producer
A Producer populates Amazon Kinesis Data Streams with records. A web server, for example, that sends log data to a stream is a producer. Consumers receive and process records from Amazon Kinesis Data Streams. Amazon Kinesis Data Streams Application is the name for these consumers.
5. Amazon Kinesis Data Streams Application
An Amazon Kinesis Data Streams application is a consumer of an Amazon Kinesis Data Streams stream, which is frequently run on a fleet of EC2 instances. Shared fan-out customers and improved fan-out customers are the two types of customers you may create.
A Kinesis Data Streams application’s output may be used as an input for another stream, allowing you to build sophisticated topologies that process data in real-time. Data can also be sent to a number of different AWS services via an application. A single stream can have several applications, each of which can consume data from the stream independently and simultaneously.
6. Shard
A shard is a succession of data records in a stream that is uniquely recognized. A stream is made up of one or more shards, each of which has a set capacity unit. Each shard can handle up to 5 read transactions per second, with a total data read at the pace of 2 MB per second, and up to 1,000 write transactions per second, with a total data write rate of 1 MB per second (including partition keys). The number of shards you set for your stream determines the data capacity of the stream. The overall capacity of the stream is equal to the sum of its shards’ capacities.
7. Partition Key
Within a stream, a partition key organizes data by shard. The data records in a stream are divided into many shards by Kinesis Data Streams. It determines which shard a particular data record belongs to by using the partition key associated with each data record. Partition keys are Unicode strings, with each key having a maximum length of 256 characters. The MD5 hash algorithm maps partition keys to 128-bit integer values and the hash key ranges of the shards also map data records to shards. A partition key must be specified when an application writes data to a stream.
8. Sequence Number
Each data record within a shard has a unique sequence number for each partition key. The sequence number is assigned by Kinesis Data Streams once you write to the stream using a . putRecords or client. putRecord. The same partition key often has an increasing sequence number over time. The size of the sequence numbers increases with the interval between write requests.
9. Kinesis Client Library
The Kinesis Client Library is a library that you may include in your application to enable fault-tolerant data consumption from the stream. The Kinesis Client Library guarantees that a record processor for each shard is operating and processing that shard. Reading data from the stream is also made easier using the library. Control data stores in an Amazon DynamoDB database via the Kinesis Client Library. It produces one table for each data-processing program.
10. Application Name
The name of an Amazon Kinesis Data Streams application is what distinguishes it from others. Each of your apps must be given a distinct name that is specific to the AWS account and region in which it runs. This name is used as a name for the control table in Amazon DynamoDB and the namespace for Amazon CloudWatch metrics
Beginning with AWS Kinesis Data Streams
1. Creating and Updating Data Streams
Amazon Kinesis Data Streams ingests a vast volume of data in real-time, stores it durably, and makes it available for use. A data record is the smallest unit of data kept by Kinesis Data Streams.
A shard is a stream of data records. You define the number of shards for a stream when you build it. A stream’s overall capacity is equal to the sum of its shards’ capacities. The number of shards in a stream can increase or decrease as needed. However, you get charge on a per-shard basis.
2. Determining the Initial Size of a Kinesis Data Stream
You must first decide on a stream’s starting size before you can build it. After you’ve created the stream, you can use the AWS Management Console or the UpdateShardCount API to dynamically scale your shard capacity up or down. While a Kinesis Data Streams application is ingesting data from the stream, you can make changes.
To determine the initial size of a stream, you need the following input values:
- The average size of the data record written to the stream in kilobytes (KB), rounded up to the nearest 1 KB, the data size (average_data_size_in_KB).
- Number of data records written to and read from the stream per second (records_per_second).
- The number of Kinesis Data Streams applications that consume data concurrently and independently from the stream, that is, the consumers (number_of_consumers).
- Incoming write bandwidth in KB (incoming_write_bandwidth_in_KB), which is equal to the average_data_size_in_KB multiplied by the records_per_second.
- The outgoing read bandwidth in KB (outgoing_read_bandwidth_in_KB), which is equal to the incoming_write_bandwidth_in_KB multiplied by the number_of_consumers.
You can calculate the initial number of shards (number_of_shards) that your stream needs by using the input values in the following formula –
number_of_shards = max(incoming_write_bandwidth_in_KiB/1024, outgoing_read_bandwidth_in_KiB/2048)
3. Creating a Stream
- You can create a stream using the Kinesis Data Streams console, the Kinesis Data Streams API, or the AWS Command Line Interface (AWS CLI).
- To create a data stream using the console
- Sign in to the AWS Management Console and open the Kinesis console at https://console.aws.amazon.com/kinesis.
- In the navigation bar, expand the Region selector and choose a Region.
- Choose Create data stream.
- On the Create Kinesis stream page, enter a name for your stream and the number of shards you need. And then click Create Kinesis stream.
- On the Kinesis streams page, your stream’s Status is Creating while the stream is being created. When the stream is ready to use, the Status changes to Active.
- Choose the name of your stream. The Stream Details page displays a summary of your stream configuration, along with monitoring information.
4. Updating a Stream Using the API
To update stream details using the API, see the following methods:
- AddTagsToStream
- DecreaseStreamRetentionPeriod
- DisableEnhancedMonitoring
- EnableEnhancedMonitoring
- IncreaseStreamRetentionPeriod
- RemoveTagsFromStream
- StartStreamEncryption
- StopStreamEncryption
- UpdateShardCount
Producers of Amazon Kinesis Data Streams – A producer adds data records to Amazon Kinesis data streams. A producer is, for example, a web server that sends log data to a Kinesis data stream. Consumer process the data records from a stream. You must supply the stream’s name, a partition key, and the data blob to add to the stream in order to add data to it. The partition key identifies which shard in the stream the data record adds.
The shard’s data is all transmitted to the same job that is processing the shard. The partition key you employ is by the logic of your application. In most cases, the number of partition keys should be significantly more than the number of shards. This is due to the fact that the partition key affects how a data record maps to a certain shard. The data can uniformly disperse across the shards in a stream if you have enough partition keys.
5. Kinesis Data Streams Consumers
An Amazon Kinesis Data Streams application, also known as a consumer, is an application that you create to read and process data records from Kinesis data streams. Instead of designing a consumer application, you may utilize the Kinesis Data Firehose delivery stream to transmit stream records straight to Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), or Splunk.
When you create a consumer, you can add it to one of your Amazon Machine Images and deploy it to an Amazon EC2 instance (AMIs). You may scale the consumer by using an Auto Scaling group to run it on numerous Amazon EC2 instances. If an EC2 instance fails, an Auto Scaling group automatically launches fresh instances. It may also dynamically scale the number of instances as the application’s load varies. Auto Scaling groups guarantee that a set number of EC2 instances is always available. You may use metrics like CPU and memory consumption to scale up or down the number of EC2 instances processing data from the stream to trigger scaling events in the Auto Scaling group.
6. Kinesis Data Streams Quotas and Limits
Amazon Kinesis Data Streams has the following stream and shard quotas and limits.
- There is no limit to how many streams you may have on your account.
- For the following AWS regions: US East (North Carolina), US West (Oregon), and Europe, the default shard quota is 500 shards per AWS account (Ireland). The default shard quota for all other locations is 200 shards per AWS account.
- Follow the steps in Requesting a Quota Increase to seek a quota increase for shards per data stream.
- A single shard may read up to 1 megabyte of data per second (including partition keys) and write up to 1,000 records per second. Similarly, scaling your stream to 5,000 shards allows it to absorb up to 5 GB per second, or 5 million records per second. If you need more ingest capacity, use the AWS Management Console or the UpdateShardCount API to increase the number of shards in the stream.
- Before base64 encoding, a record’s data payload can be up to 1 MB in size.
- GetRecords may get up to 10 MB of data and 10,000 records per request from a single shard. Each GetRecords call counts as a single read transaction.
- Each shard. supports Up to five read transactions per second.
- Then, with a maximum capacity of 10 MB per transaction, each read operation can deliver up to 10,000 records.
- Through GetRecords, each shard may handle a maximum total data read rate of 2 MB per second. If GetRecords returns 10 MB, all further requests within 5 seconds will raise an exception.
