Manage compute for dedicated SQL pool in Azure Synapse Analytics
In this we will learn about managing compute resources dedicated SQL pool (formerly SQL DW) in Azure Synapse Analytics. Reduce expenses by suspending the dedicated SQL pool, or increase performance by scaling the dedicated SQL pool.
Compute management
- Storage and computing are separated in the dedicated SQL pool (previously SQL DW) design, letting each to scale independently.
- As a result, regardless of data storage, you may increase computing to match performance objectives.
- Additionally, you can halt and resume compute resources. However, this design has the unintended consequence of paying computation and storage separately.
- You can save compute expenses by suspending compute if you don’t need to utilise your dedicated SQL pool (previously SQL DW) for a while.
Scaling compute
- By modifying the data warehouse units option for your dedicated SQL pool, you may scale out or scale down computation (formerly SQL DW).
- As you add more data warehouse units, loading and query speed can improve linearly.
- In addition, while performing a scaling operation, the dedicated SQL pool (previously SQL DW) terminates all incoming queries before rolling back transactions to maintain consistency.
- Once the transaction rollback is complete, scaling takes place.
- The system detaches the storage layer from the compute nodes during a scaling operation, then adds compute nodes before reattaching the storage layer to the Compute layer.
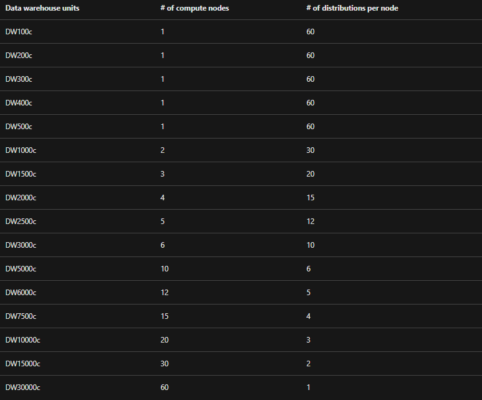
- Further, each dedicated SQL pool (previously SQL DW) is saved as 60 distributions that are divided evenly across the compute nodes. Increasing the number of compute nodes increases the amount of compute power available.
- The number of distributions per compute node lowers as the number of compute nodes rises, offering greater computing power for your queries. Similarly, reducing data warehouse units decreases the number of compute nodes, lowering query computing requirements.
The table below demonstrates how the number of distributions per Compute node changes as the number of data warehouse units increases. DW30000c has 60 compute nodes and performs substantially better than DW100c in terms of query performance.
Finding the right size of data warehouse units
Recommendations for finding the best number of data warehouse units:
- Firstly, for a dedicated SQL pool (formerly SQL DW) in development, begin by selecting a smaller number of data warehouse units. A good starting point is DW400c or DW200c.
- Secondly, monitor your application performance, observing the number of data warehouse units selected compared to the performance you observe.
- Thirdly, assume a linear scale, and determine how much you need to increase or decrease the data warehouse units.
- Lastly, continue making adjustments until you reach an optimum performance level for your business requirements.

When to scale out
Scaling out data warehouse units impacts these aspects of performance:
- Firstly, linearly improves performance of the system for scans, aggregations, and CTAS statements.
- Secondly, increases the number of readers and writers for loading data.
- Lastly, maximum number of concurrent queries and concurrency slots.
Recommendations for when to scale out data warehouse units:
- Firstly, before you perform a heavy data loading or transformation operation, scale out to make the data available more quickly.
- Secondly, during peak business hours, scale out to accommodate larger numbers of concurrent queries.
Pausing and resuming compute
When you pause computing, the storage layer separates from the compute nodes. Your account’s computational resources have been freed. You are not charged for compute while it is halted, though. Resuming compute reconnects storage to the Compute nodes and reactivates Compute charges. When you suspend a dedicated SQL pool (previously SQL DW), you must do the following:
- Firstly, compute and memory resources are returned to the pool of available resources in the data center
- Secondly, data warehouse unit costs are zero for the duration of the pause.
- Thirdly, data storage is not affected and your data stays intact.
- Lastly, all running or queued operations are cancelled.
When you resume a dedicated SQL pool (formerly SQL DW):
- Firstly, the dedicated SQL pool (formerly SQL DW) acquires compute and memory resources for your data warehouse units setting.
- Secondly, compute charges for your data warehouse units resume.
- Then, your data becomes available.
- Lastly, after the dedicated SQL pool (formerly SQL DW) is online, you need to restart your workload queries.
Drain transactions before pausing or scaling
- We recommend allowing existing transactions to finish before you initiate a pause or scale operation. Furthermore, when you stop or scale your dedicated SQL pool (previously SQL DW), your queries are aborted behind the scenes when you request the pause or scale.
- Cancelling a basic SELECT query is a short action that has little influence on the amount of time it takes to stop or grow your instance.
- Transactional queries, on the other hand, may not be able to end immediately if they affect your data or its structure.
- By definition, transactional queries must either finish in their entirety or rollback their modifications. Rolling back a transactional query’s operation can take as long as, if not longer than, the initial change the query was making.

Reference: Microsoft Documentation