Understanding Kinesis Data Streams
Amazon Kinesis Data Streams can
- collect and process large streams of data records in real time.
- create data-processing applications called Kinesis Data Streams applications.
- Kinesis Data Streams application reads data from a data stream as data records.
- use for rapid and continuous data intake and aggregation.
- Input data includes data from logs, social media, market feeds and web clickstream.
- processing is typically lightweight.
- Streams (collect & process large streams of data in real time),
- Analytics(run standard SQL queries against streaming data),
- Firehouse(load streaming data into AWS from many sources into S3 and Redshift)
- Kinesis Streams vs SQS – Kinesis for data processing at same time or within 24 hrs by different consumers, data can reuse with in 24 hrs
- 24 hrs retention
- SQS can write multiple queue using fanout, data cannot be reused, 14 days retention
High-level architecture of Kinesis Data Streams –
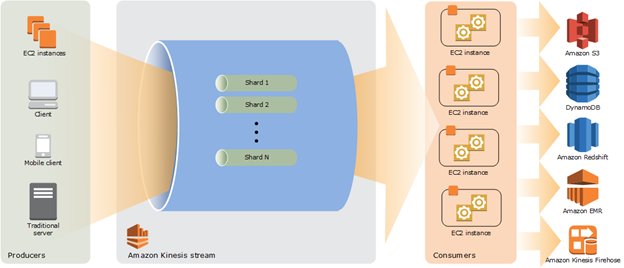
- Producers continually push data to Kinesis Data Streams
- consumers process data in real time.
- Consumers can be custom application running on Amazon EC2 or Amazon Kinesis Data Firehose delivery stream
- Store their results using AWS DynamoDB, Redshift, or S3.
Kinesis Data Streams Terminology
Kinesis Data Stream
A Kinesis data stream is a set of shards. Each shard has a sequence of data records. Each data record has a sequence number assign by Kinesis Data Streams.
Data Record
A data record is unit of data in a Kinesis data stream. Data records contains a sequence number, a partition key, and a data blob, which is an immutable sequence of bytes. Kinesis Data Streams does not inspect, interpret, or change data in blob in any way. A data blob can be up to 1 MB.
Retention Period
Retention period is length of time that data records are accessible after they add to stream. A stream’s retention period is set to a default of 24 hours after creation. You can increase retention period up to 168 hours (7 days) using IncreaseStreamRetentionPeriod operation, and decrease retention period down to a minimum of 24 hours using DecreaseStreamRetentionPeriod operation. Additional charges apply for streams with a retention period set to more than 24 hours.
Producer
Producers put records into Amazon Kinesis Data Streams. For example, a web server sending log data to a stream is a producer.
Consumer
Consumers get records from Amazon Kinesis Data Streams and process them. These consumers are Amazon Kinesis Data Streams Application.
Amazon Kinesis Data Streams Application
An Amazon Kinesis Data Streams application is a consumer of a stream that commonly runs on a fleet of EC2 instances. There are two types of consumers that you can develop: shared fan-out consumers and enhanced fan-out consumers.
Shard
A shard is a uniquely identified sequence of data records in a stream. A stream is a mixture of one or more shards, each of which provides a fixed unit of capacity. Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys). data capacity of stream is a function of number of shards that you specify for stream. total capacity of stream is sum of capacities of its shards.
Partition Key
A partition key can group data by shard within a stream. Kinesis Data Streams segregates data records belonging to a stream into multiple shards. It uses partition key associated with each data record to determine which shard a given data record belongs to. Partition keys are Unicode strings with a maximum length limit of 256 bytes. An MD5 hash function map partition keys to 128-bit integer values and to map associated data records to shards. When an application puts data into a stream, it must specify a partition key.
Sequence Number
Each data record has a sequence number that is unique per partition-key within its shard. Kinesis Data Streams assigns sequence number after you write to stream with client.putRecords or client.putRecord. Sequence numbers for same partition key generally increase over time. longer time period between write requests, larger sequence numbers become.
Kinesis Client Library
Kinesis Client Library compiles into application to enable fault-tolerant consumption of data from stream. This ensures that for every shard there is a record processor running and processing that shard. library also simplifies reading data from stream. Kinesis Client Library uses an Amazon DynamoDB table to store control data. It creates one table per application that is processing data.
AWS Kinesis Summary
Data Structures
- unit of data stored by Kinesis Data Streams is a data record.
- A stream represents a group of data records.
- data records in a stream are distributed into shards.
- A shard has a sequence of data records in a stream.
Stream Creation
- When you create a stream, specify number of shards for stream.
- Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second.
- Shards support up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys).
- total capacity of a stream is sum of capacities of its shards.
- Increase or decrease number of shards in a stream as needed.
- You are charged on a per-shard basis. Billing is per shard provisioned, can have as many shards as you want. Records are ordered per shard.
Kinesis Data Stream
- Kinesis data stream, is composed of
- a sequence number or unique ID of record within its shard. Type: String
- partition key -identifies which shard in stream data record is assigned to. Type: String
- data blob – Data in blob is opaque and immutable so it is not inspected, interpreted, or changed in any way.
- When data blob, payload before base64-encoding, is added to partition key size, total size must not exceed maximum record size of 1 MB. Type: Base64-encoded binary data object.
- Use server-side data encryption for sensitive data using Amazon Kinesis Data Firehose but, Kinesis stream as data source is necessary, though data is stored in Kinesis stream.
- When you send data to Kinesis stream, data encrypts using an AWS KMS key before storing it at rest.
- When Kinesis Data Firehose delivery stream reads data from Kinesis stream, Kinesis Data Streams service first decrypts data and then sends it to Kinesis Data Firehose. Kinesis Data Firehose buffers data in memory based on buffering hints that you specify and then delivers it to destinations without storing unencrypted data at rest.
- In Kinesis, to prevent skipped records, handle all exceptions within processRecords appropriately.
- If data delivery to Redshift fail from Kinesis Firehose , Amazon Kinesis Firehose retries data delivery every 5 minutes for up to a maximum period of 60 minutes. After 60 minutes, Amazon Kinesis Firehose skips current batch of S3 objects that are ready for COPY and moves on to next batch. information about skipped objects is delivered to S3 bucket as a manifest file in errors folder, which you can use for manual backfill.
Amazon Kinesis Data Streams limits.
- No upper limit on number of shards in a stream or account may be thousands.
- No upper limit on number of streams you can have in an account.
- A single shard can ingest up to 1 MiB of data per second (including partition keys) or 1,000 records per second for writes. So, stream with 5,000 shards, it can ingest up to 5 GiB per second or 5 million records per second. Add number of shards in stream using AWS Management Console or UpdateShardCount API for more ingest capacity.
- Default shard limit is 500 shards for following AWS Regions: US East (N. Virginia), US West (Oregon), and EU (Ireland). For all other Regions, default shard limit is 200 shards.
- maximum size of data payload of a record before base64-encoding is up to 1 MiB.
- GetRecords can retrieve up to 10 MiB of data per call from a single shard, and up to 10,000 records per call. Each call to GetRecords counts as one read transaction.
- Each shard can support up to five read transactions per second. Further, each read transaction can provide up to 10,000 records with an upper limit of 10 MiB per transaction.
- Each shard can support up to a maximum total data read rate of 2 MiB per second via GetRecords. If a call to GetRecords returns 10 MiB, subsequent calls made within next 5 seconds throw an exception.
Creating a Stream in Amazon Kinesis
A stream can be created by
- Kinesis Data Streams console
- Kinesis Data Streams API
- AWS Command Line Interface (AWS CLI).
Steps to create a data stream using console
- Sign in to AWS Management Console and open Kinesis console at https://console.aws.amazon.com/kinesis.
- In navigation bar, expand Region selector and choose a Region.
- Choose Create data stream.
- On Create Kinesis stream page, enter a name for stream and number of shards you need, and then click Create Kinesis stream.
- On Kinesis streams page, stream’s Status is Creating while stream is being created. When stream is ready to use, Status changes to Active.
- Choose name of stream. Stream Details page displays a summary of stream configuration, along with monitoring information.
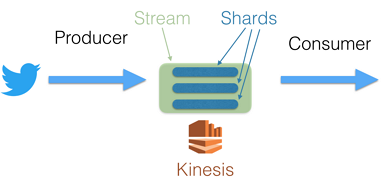
Kinesis Data Streams Producers
A producer puts data records into Amazon Kinesis data streams. For example, a web server sending log data to a Kinesis data stream is a producer.
To put data into stream following is necessary:
- name of stream
- a partition key, it determines which shard in stream data record adds to and is as per application logic. Its count is usually greater than number of shards for evenly distribution
- data blob to adds to stream.
All data in shard is sent to same worker that is processing shard.
Using KPL
- KPL is an easy-to-use, highly configurable library, to write to Kinesis data stream.
- KPL writes with an automatic and configurable retry mechanism
- Acts as an intermediary between producer application code and Kinesis Data Streams API actions.
- Collects records and uses PutRecords to write multiple records to multiple shards per request
- Aggregates user records to increase payload size and improve throughput
- Integrates seamlessly with Kinesis Client Library (KCL) to de-aggregate batched records on consumer
- Submits Amazon CloudWatch metrics on behalf to provide visibility into producer performance
Using Amazon Kinesis Data Streams API –
- Develop producers using Amazon Kinesis Data Streams API with AWS SDK for Java.
- Two different operations to add data to a stream – PutRecords and PutRecord.
- PutRecords sends multiple records to stream per HTTP request,
- PutRecord operation sends records to stream one at a time (a separate HTTP request is necessary for each record).
Using Kinesis Agent –
- Kinesis Agent is a stand-alone Java software application
- It easily collects and sends data to Kinesis Data Streams.
- agent continuously monitors a set of files and sends new data to stream.
- agent handles file rotation, checkpointing, and retry upon failures.
- It delivers all of data in a reliable, timely, and simple manner.
- It also emits Amazon CloudWatch metrics to help you better monitor and troubleshoot streaming process.
- By default, records parses from each file based on newline (‘\n’) character.
- Operating system must be either Amazon Linux AMI with version 2015.09 or later, or Red Hat Enterprise Linux version 7 or later.
Consumers with Enhanced Fan-Out
- Enhanced fan-out, enables consumers to receive records from a stream with throughput of up to 2 MiB of data per second per shard.
- This throughput is dedicated, which means that consumers that use enhanced fan-out don’t have to contend with other consumers that are receiving data from stream.
- Kinesis Data Streams pushes data records from stream to consumers that use enhanced fan-out.
- Therefore, these consumers don’t need to poll for data.
- You can register up to five consumers per stream to use enhanced fan-out.
- If you need to register more than five consumers, you can request a limit increase
Splitting a Shard –
- Need to specify how hash key values from parent shard should redistribute to child shards.
- When you add a data record to a stream, it get assign to a shard depending on a hash key value.
- hash key value is MD5 hash of partition key that you specify for data record at time that you add data record to stream.
- Data records that have same partition key also have same hash key value.
Merging Two Shards –
- It takes two specified shards and combines them into a single shard.
- After merge, single child shard receives data for all hash key values covered by two parent shards.
- shards must be adjacent, for merging.
- Considered adjacent, if union of hash key ranges for two shards forms a contiguous set with no gaps. For example, two shards, hash key range of 276…381 and 382…454, can merge into a single shard that would have a hash key range of 276…454.
Kinesis Data Streams Consumers
- A consumer, or Amazon Kinesis Data Streams application, reads and processes data records from Kinesis data streams.
- To send stream records directly to services like Amazon S3, Redshift, Elasticsearch Service or Splunk, use a Kinesis Data Firehose delivery stream instead of creating a consumer application.