Query Temporal Data and Non-Relational Data
Introducing JSON for SQL Server 2016
JSON stands for JavaScript Object Notation. It is mainly used to store and exchange information. JSON data is well organized, easy-to-access and in human-readable format of data that can be accessed in a logical manner.
Some of the features of JSON are –
- JSON is self-describing and easy to understand
- JSON is a lightweight data-interchange format
- JSON is language independent
- JSON is used primarily to transmit data between a server and web application, as an alternative to XML
Sample JSON Format

Most of the major databases are adopting JSON support because the usage of JSON in Web APIs has increased significantly. SQL Server 2016 also enabled JSON support for the lingua franca* of web applications in addition to supporting direct querying to Hadoop. JSON functionality in SQL Server is similar to XML Support.
JSON Functionality in SQL Server
JSON features that are planned in SQL Server 2016…
- SQL SERVER CTP2 – Format and export the data in JSON Format
- SQL SERVER CTP3 – Extract and Load the JSON into Tables, seeking values from JSON text, index the column which has JSON data, etc.
JSON Features in CTP2
- For JSON [AUTO | PATH] – We can get the JSON output by adding the “For JSON” clause in a SELECT statement. We can generate the JSON in two different modes, we will look at each option in the below sections.
JSON Functionality Expected in CTP3
The features listed below are expected to be available as part of CTP3:
- OPENJSON – OPENJSON is a table-value function, which accepts some text which includes a JSON value and returns rows in the required format. FOR JSON, converts the rows into JSON format, but OPENJSON will convert back the JSON text into a table of rows.
- IsJSON (< JSON text >) – This function verifies, whether the given text is formatted according to JSON standards/rules.
- JSON_Value () – This is a scalar function and it parses the JSON text then extracts a value if it exists in the path arguments. This functionality is similar to XPATH (XML Path) which is used for selecting nodes from XML text. In addition, XPath may be used to compute values (e.g. strings, numbers or Boolean values) from the content of an XML document.
JSON in SQL Server
To store JSON data in SQL Server, we have to use an NVARCHAR datatype because there is no separate datatype for JSON data. NVARCHAR supports the storage of most of the data types and now is extended to handle JSON as well.
JSON data in SQL Server
JSON is a popular textual data format that’s used for exchanging data in modern web and mobile applications. JSON is also used for storing unstructured data in log files or NoSQL databases such as Microsoft Azure Cosmos DB. Many REST web services return results that are formatted as JSON text or accept data that’s formatted as JSON. For example, most Azure services, such as Azure Search, Azure Storage, and Azure Cosmos DB, have REST endpoints that return or consume JSON. JSON is also the main format for exchanging data between webpages and web servers by using AJAX calls.
JSON functions in SQL Server enable you to combine NoSQL and relational concepts in the same database. Now you can combine classic relational columns with columns that contain documents formatted as JSON text in the same table, parse and import JSON documents in relational structures, or format relational data to JSON text.
Example of JSON Text
[{“name”: “John”,
“skills”: [“SQL”, “C#”, “Azure”] }, {
“name”: “Jane”,
“surname”: “Doe”
}]
By using SQL Server built-in functions and operators, you can do the following things with JSON text:
- Parse JSON text and read or modify values.
- Transform arrays of JSON objects into table format.
- Run any Transact-SQL query on the converted JSON objects.
- Format the results of Transact-SQL queries in JSON format.
Extract values from JSON text and use them in queries
If you have JSON text that’s stored in database tables, you can read or modify values in the JSON text by using the following built-in functions –
- ISJSON (Transact-SQL) tests whether a string contains valid JSON.
- JSON_VALUE (Transact-SQL) extracts a scalar value from a JSON string.
- JSON_QUERY (Transact-SQL) extracts an object or an array from a JSON string.
- JSON_MODIFY (Transact-SQL) changes a value in a JSON string.
Introduction to SQL Server Temporal Tables
Temporal tables were introduced in the ANSI SQL 2011 standard and has been released as part of SQL Server 2016. A system-versioned table allows you to query updated and deleted data, while a normal table can only return the current data. For example, if you update a column value from 5 to 10, you can only retrieve the value 10 in a normal table. A temporal table also allows you to retrieve the old value 5. This is accomplished by keeping a history table. This history table stores the old data together with a start and end data to indicate when the record was active.
What is a system-versioned temporal table?
A system-versioned temporal table is a type of user table designed to keep a full history of data changes and allow easy point in time analysis. This type of temporal table is referred to as a system-versioned temporal table because the period of validity for each row is managed by the system (i.e. database engine).
Every temporal table has two explicitly defined columns, each with a datetime2 data type. These columns are referred to as period columns. These period columns are used exclusively by the system to record period of validity for each row whenever a row is modified.
In addition to these period columns, a temporal table also contains a reference to another table with a mirrored schema. The system uses this table to automatically store the previous version of the row each time a row in the temporal table gets updated or deleted. This additional table is referred to as the history table, while the main table that stores current (actual) row versions is referred to as the current table or simply as the temporal table. During temporal table creation users can specify existing history table (must be schema compliant) or let system create default history table.
Why temporal?
Real data sources are dynamic and more often than not business decisions rely on insights that analysts can get from data evolution. Use cases for temporal tables include –
- Auditing all data changes and performing data forensics when necessary
- Reconstructing state of the data as of any time in the past
- Calculating trends over time
- Maintaining a slowly changing dimension for decision support applications
- Recovering from accidental data changes and application errors
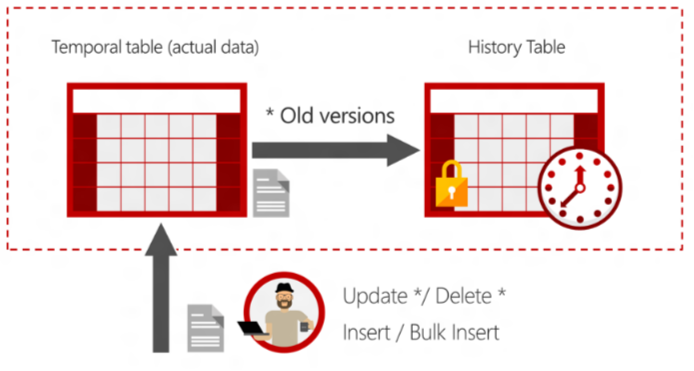
How does temporal work?
System-versioning for a table is implemented as a pair of tables, a current table and a history table. Within each of these tables, the following two additional datetime2 columns are used to define the period of validity for each row:
- Period start column: The system records the start time for the row in this column, typically denoted as the SysStartTime column.
- Period end column: The system records the end time for the row in this column, typically denoted as the SysEndTime column.
The current table contains the current value for each row. The history table contains each previous value for each row, if any, and the start time and end time for the period for which it was valid.
Most common use cases for Temporal Tables
- Audit – With temporal tables you can find out what values a specific entity has had over its entire lifetime.
- Slowly changing dimensions – A system-versioned table exactly behaves like a dimension with type 2 changing behavior for all of its columns.
- Repair record-level corruptions – Think of it as a sort of back-up mechanism on a single table. Accidentally deleted a record? Retrieve it from the history table and insert it back into the main table.
Temporal tables or system-versioned tables are an example of an assertion table, meaning that it captures the lifetime of a record based on the physical dates the record was removed or updated. Temporal tables currently do not support versioning, meaning the versioning of records based on logical dates.
Note that temporal tables are not a replacement for the change data capture (CDC) feature. CDC uses the transaction log to find the changes and typically those changes are kept for a short period of time (depending on your ETL timeframe). Temporal tables store the actual changes in the history table and they are intended to stay there for a much longer time.
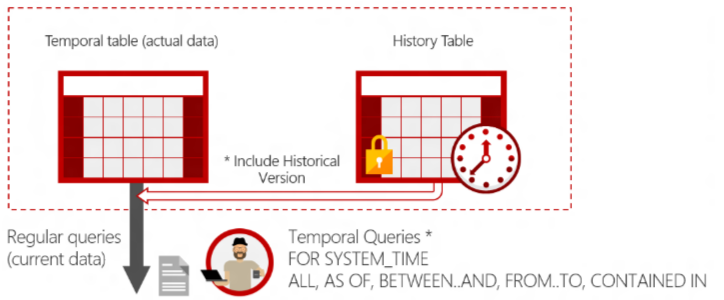
How do I query temporal data?
The SELECT statement FROM<table> clause has a new clause FOR SYSTEM_TIME with five temporal-specific sub-clauses to query data across the current and history tables. This new SELECT statement syntax is supported directly on a single table, propagated through multiple joins, and through views on top of multiple temporal tables.
Creating a system-versioned table
When you want to create a new temporal table, a couple of prerequisites must be met:
- A primary key must be defined
- Two columns must be defined to record the start and end date with a data type of datetime2. If needed, these columns can be hidden using the HIDDEN flag. These columns are called the SYSTEM_TIME period columns.
- INSTEAD OF triggers are not allowed. AFTER triggers are only allowed on the current table.
- In-memory OLTP cannot be used in SQL Server 2016. Later on, this limitation has been lifted. Check out the documentation for more information.
- By default, the history table is page compressed.
- ON DELETE/UPDATE CASCADE is not permitted on the current table. This limitation has also been lifted in SQL Server 2017.
Limitations of Temporal Tables
- Temporal and history table cannot be FILETABLE
- The history table cannot have any constraints
- INSERT and UPDATE statements cannot reference the SYSTEM_TIME period columns
- Data in the history table cannot be modified
Script to create a simple system-versioned table
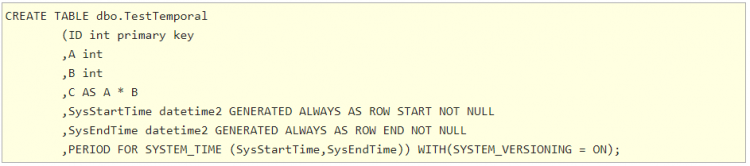
In case you don’t specify a name for the history table, SQL Server will automatically generate one of the following structure – dbo.MSSQL_TemporalHistoryFor_xxx, where xxx is the object id of the main table.
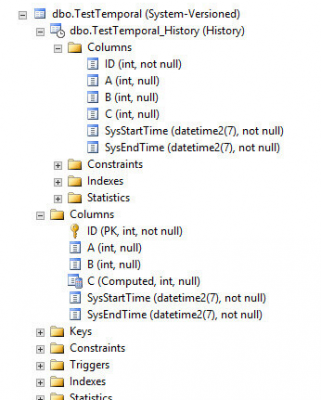
Alter the schema of a system-versioned table
In SQL Server 2016, when system-versioning is enabled on a table, modifications on the table are severely limited. These were the allowed modifications:
- ALTER TABLE … REBUILD
- CREATE INDEX
- CREATE STATISTICS
All other schema modifications are disallowed. However, in SQL Server 2017 many limitations were removed.
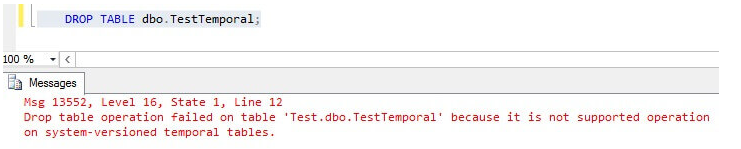
When we alter the schema of the table and the modification is not supported then in that case, system-versioning has to be disabled first –
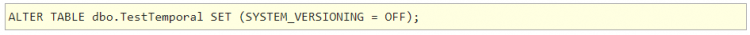
This command will remove system_versioning and turn the main table and the history table into two regular tables.
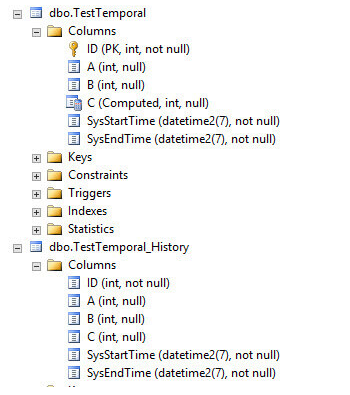
We can do any modifications that we like on both tables. But ensure they stay in sync and history is still consistent. After the modifications, you can turn system-versioning back on.

