
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a completely managed service that executes it easy for us to develop and run applications that utilize Apache Kafka to concoct streaming data. Apache Kafka is an open-source principle for creating real-time streaming data applications and pipelines. With Amazon MSK, we can work native Apache Kafka APIs to populate data lakes, stream changes to and from databases, and power machine knowledge and analytics applications.
Further, Apache Kafka clusters are stimulating to set up, scale, and maintain in production. When we run Kafka on our own, we require to provision servers, configure Apache Kafka manually, restore servers when they fail, harmonize server patches and upgrades, architect the cluster for high availability, guarantee data is durably saved and secured, settings monitoring and alarms, and carefully plan to scale events to support load changes. Also, Amazon MSK makes it easy for us to create and administer production applications on Kafka without requiring Apache Kafka infrastructure administration expertise. That means we employ less time maintaining infrastructure and more time constructing applications.
What is Apache Kafka?
Apache Kafka is a classified data store optimized for processing and ingesting streaming data in real-time. Streaming data is information that is continuously produced by thousands of data sources, which typically transmit the data records together. A streaming platform requires to manage this continuous influx of data, and prepare the data sequentially and incrementally.
Kafka implements 3 main purposes to its users:
- Publish and subscribe to streams of records
- Alao, effectively save streams of records in the order in which records were produced
- Process streams of records in real time
Kafka is originally used to establish real-time streaming data pipelines and applications that conform to the data streams. It blends messaging, storage, and stream processing to provide storage and analysis of both historical and real-time data.

Kafka’s architecture
Kafka helps the two separate models by printing records to various topics. Each topic has a partitioned log, which is a structured commit log that keeps a record of all records in order and supplements new ones in real-time. These partitions are disseminated and replicated across various servers, permitting for high scalability, fault tolerance, and parallelism. Each customer is appointed a partition in the topic, which acknowledges multi-subscribers while sustaining the order of the data. By connecting these messaging models, Kafka gives the advantages of both. Kafka also acts as a scalable and fault-tolerant accommodation system by writing and replicating all data to disk. By default, Kafka keeps data stored on a disk until it runs out of space, but the user can also set a retention limit. Kafka has four APIs:
- Producer API: It used to publish a stream of records to a Kafka topic.
- Consumer API: used to subscribe to topics and process their streams of records.
- Streams API: enables applications to behave as stream processors, which take in an input stream from topic(s) and transform it to an output stream which goes into different output topic(s).
- Connector API: allows users to seamlessly automate the addition of another application or data system to their current Kafka topics.
With several clicks in the Amazon MSK console, we can make extremely available Apache Kafka clusters with configuration and settings based on Apache Kafka’s deployment best works. Amazon MSK automatically reserves and runs the Kafka clusters. In addition, Amazon MSK continuously observes cluster health and automatically substitutes unhealthy nodes with no downtime to the application. Amazon MSK secures our Apache Kafka cluster by encrypting data at rest. Let us now discuss some advantages of Amazon MSK!
Benefits of Amazon Managed Streaming for Apache Kafka
Following are some benefits that we should know.
Fully compatible
Amazon MSK operates and maintains Apache Kafka for us. This makes it simple for us to transfer and run our current Kafka applications on AWS without modifications to the application code. By utilizing Amazon MSK, we sustain open-source adaptability and can proceed to use simple custom and community-built devices such as Apache Flink, MirrorMaker, and Prometheus.
Fully managed
Amazon MSK lets us focus on building our streaming applications without worrying about the operational burden of managing the Apache Kafka environment. Further, the Amazon MSK operates the configuration, provisioning, and sustenance of the Apache Kafka clusters and Apache ZooKeeper nodes for us. Amazon MSK also bestows key Apache Kafka performance metrics in the AWS console.
Elastic stream processing
Apache Flink is a potent, open-source stream processing structure for stateful estimates of streaming data. We can operate completely managed Apache Flink applications drafted in Java, SQL, or Scala that elastically balance to process data streams within the Amazon MSK.
Highly available
Amazon MSK constitutes an Apache Kafka batch and allows multi-AZ replication inside an AWS Region. Further, Amazon MSK constantly observes cluster health, and if an element fails, Amazon MSK will automatically substitute it.
Highly secure
Amazon MSK gives various levels of security for our Apache Kafka clusters incorporating VPC network isolation, encryption at rest, AWS IAM for control-plane API authorization, TLS based certificate authentication, SASL/SCRAM authentication secured by AWS Secrets Manager, TLS encryption in-transit, and maintains (ACLs) Apache Kafka Access Control Lists for the data-plane authorization.
How does it works?
Apache Kafka is a streaming data repository that decouples applications providing streaming data (producers) into its data store from applications consuming streaming data (consumers) from its data store. Companies use Apache Kafka as a data reference for applications that constantly investigate and react to the streaming data. The following diagram provides an overview of how Amazon MSK works.
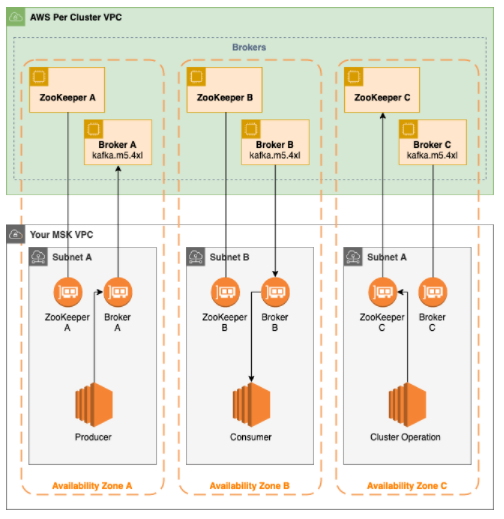
The diagram shows the interaction among the following elements:
- Broker nodes — When making an Amazon MSK cluster, we should specify how many broker nodes we require Amazon MSK to create in each Availability Zone. In the example cluster shown in this diagram, there’s 1 broker per Availability Zone. Each Availability Zone has its own (VPC) virtual private cloud subnet.
- ZooKeeper nodes — Amazon MSK also makes the Apache ZooKeeper nodes for us. Apache ZooKeeper is an open-source server that provides extremely reliable distributed coordination.
- Producers, consumers, and topic creators — Amazon MSK lets us use the Kafka data-plane operations to make topics and to produce and consume the data.
- Cluster Operations – We can utlilize the AWS Management Console, the (AWS CLI) AWS Command Line Interface, or the APIs in the SDK to execute control-plane operations. For instance, we can make or remove an Amazon MSK cluster, list all the clusters in an account, view the properties of a cluster, and update the number and type of brokers in a cluster.
Amazon MSK recognizes and automatically gains from the most frequent failure situations for clusters so that our producer and consumer applications can maintain their write and read processes with minimum impact. When Amazon MSK discovers a broker failure, it decreases the failure or substitutes the invalid or unreachable broker with a distinct one. Further, where possible, it reuses the accommodation from the older broker to subdue the data that Kafka requires to replicate. The availability impact is restricted to the time needed for the Amazon MSK to achieve detection and regeneration. After recovery, the producer and consumer apps can proceed to communicate with the corresponding broker IP addresses that they worked on before the failure.
Why would we want to use Amazon MSK?
Amazon MSK is one of the most reliable methods to deploy the Apache Kafka in the AWS VPC securely and swiftly. The main benefits that we will get are
- Managed service: we don’t have to bring together a whole engineering team to setup the Kafka. We can start making our applications in less than 15 minutes
- Network security: Apache Kafka on the Amazon MSK is deployed within the VPC, implying that the Apache Kafka network packets never goes out on the internet. This is a huge difference from public managed solutions such as Confluent Cloud.
- Kafka security: MSK supports SSL based SASL/SCRAM and security.. We have setup Kafka security earlier, and can tell you it’s error prone and hard. We can straight use a secure Kafka cluster on MSK.
Some of the Amazon MSK customers/ Case studies
It is time to understand some MSK case studies.
New Relic– The world’s most immeasurable engineering teams rely on New Relic to reflect, analyze and troubleshoot the software. New Relic One is the most robust cloud-based observability platform established to assist companies to build more perfect software.
Nutmeg– Nutmeg is Europe’s most considerable digital wealth manager, accommodating consumers to improve their wealth and reach their financial purposes by utilizing cost-effective technology to boost arrivals. Nutmeg uses Apache Kafka to underpin its mission towards an event-driven architecture.
Poshmark– It is a front social commerce program for the next generation of shoppers and retailers. Through technology, their mission is to organize the world’s most associated shopping experience, while allowing people to produce thriving retail businesses.
Vonage– It is a global business cloud communications leader producing mixed communications solutions that change how business gets done by improving a company’s customer and employee knowledge. Vonage practices Apache Kafka for real-time communication among different micro-services.
Secureworks®– Secureworks® (NASDAQ: SCWX) is a technology-driven cybersecurity leader that defends institutions in the digitally connected world.
Compass– Compass is a sincere estate technology corporation with a compelling end-to-end platform that promotes the whole buying and selling workflow. Compass practices Apache Kafka to give its agents quick entrance to fresh and accurate data from a number of real estate data sources nationwide.
ZipRecruiter– ZipRecruiter is a principal online employment marketplace utilizing AI-driven matching technology to actively join millions of businesses and job seekers.
There are more case studies that one can refer to at https://aws.amazon.com/msk/customer-success/ !
To Conclude!
Kafka is an open-source technology that provides for a huge amount of community-driven devices and add-ons. This presents it as very customizable and gives developers the freedom to build and create what they require. Using Amazon MSK, we can practice the native Apache Kafka APIs to build data lakes, stream information to various sources, and power data analytic applications and pipelines, repeatedly all within AWS. Amazon MSK is now a very valid solution to implement the Apache Kafka on AWS. We are suggesting it to our clients for its ease of use. Start learning NOW!
