
For providing the best solution to professional developers, engineers, and scientists for efficiently running thousands of batch computing jobs, AWS came up with the Amazon Batch service. This dynamically provisions the optimal quantity and type of computing resources depending on the volume and specific resource needs of the batch jobs submitted. Moreover, with AWS Batch, there is no requirement for installing and controlling batch compute software or server clusters for conducting jobs. This helps you to focus on analyzing results and solving problems. But, what else it can do, and how does it operate?
To get an answer to this question, you have to stay connected with the blog. Here, we will cover the overall concepts of AWS Batch processing including its features, cases, and how to get started with this service.
What is Amazon Batch?
AWS Batch is used for running batch computing workloads on the AWS Cloud. However, Batch computing is a common method for developers, scientists, and engineers for accessing large amounts of computing resources. Moreover, Amazon Batch eliminates the undifferentiated heavy lifting of configuring and managing the needed infrastructure same as the traditional batch computing software. This service can efficiently provision resources in response to jobs submitted in order for:
- eliminating capacity constraints
- lowering compute costs
- delivering results quickly.

Components of Amazon Batch:
AWS Batch simplifies running batch jobs over multiple Availability Zones inside a Region. You can create AWS Batch compute environments and associate them with a job queue. Then, you can define job definitions that specify which Docker container images are for running your jobs. Further, container images are placed in and pulled from container registries, which may exist inside or outside of AWS infrastructure.
1. Jobs
This refers to a unit of work that you submit to AWS Batch. This contains a name and runs as a containerized application on AWS Fargate or Amazon EC2 resources in your computing environment, using parameters that you specify in a job definition. Further, jobs can reference other jobs by name or by ID. And, tit can be dependent on the successful completion of other jobs.
2. Job Definitions
A job definition specifies the running process of the job. This is basically a blueprint for the resources in your job. That is to say, you can supply your job with an IAM role for providing access to other AWS resources. Moreover, the job definition can also manage container properties, environment variables, and mount points for persistent storage.
3. Job Queues
While submitting an AWS Batch job, you submit it to a particular job queue, where the job stays until it’s scheduled onto a computing environment. Further, you can also link one or more compute environments with a job queue and allocate priority values for these compute environments over job queues themselves.
4. Compute Environment
A computing environment can be considered as a set of managed or unmanaged compute resources used for running jobs. Where managed to compute environments help in defining desired compute types at various levels of detail. Moreover, you can construct compute environments that use a specific type of EC2 instance. Further, you can also define the minimum, desired, and maximum number of vCPUs for the environment. And, you can also define the amount you are paying for a Spot Instance.
What are the features of AWS Batch?
AWS Batch allows you to simply package the code for your batch jobs, define their dependencies, and then, submit your batch job using the AWS Management Console, CLIs, or SDKs. To work these out, AWS Batch comes with loaded features that help in running these processes. Let’s understand them.
1. Dynamic compute resource provisioning and scaling
- While using Fargate or Fargate Spot with Batch, you only require to set up a few concepts in Batch. This automatically provides a full queue, scheduler, and compute architecture without any need for managing a single compute infrastructure.
- Moreover, for those requiring EC2 instances, AWS Batch also offers Managed Compute Environments that dynamically provision and scale compute resources depending on the volume and resource requirements of your submitted jobs.
- At last, you can provision and manage your own compute resources inside AWS Batch Unmanaged Compute Environments. This is best if you require using different configurations for your EC2 instances than what is offered by AWS Batch Managed Compute Environments.
2. AWS Batch with Fargate
- AWS Batch with Fargate resources provides access to have a serverless architecture for your batch jobs. Using this, every job receives the exact amount of CPU and memory that it requests. However, for the current Batch users, then Fargate allows an additional layer of separation apart from EC2. That is to say, there is no need for managing or patching AMI.
- Moreover, you don’t even need for worrying about maintaining two different services while submitting your Fargate-compatible jobs to Batch if you have workloads that run on EC2, and others that run on Fargate.
3. Support for tightly-coupled HPC workloads
- AWS Batch supports multi-node parallel jobs which provide access for running single jobs that span multiple EC2 instances.
- This feature allows the use of AWS Batch for efficiently running workloads like large-scale, tightly-coupled High-Performance Computing (HPC) applications or distributed GPU model training.
- Further, AWS Batch also supports Elastic Fabric Adapter, a network interface for running applications that need high levels of inter-node communication at scale on AWS.
4. Granular job definitions and simple job dependency modeling
- AWS Batch provides access for specifying resource requirements like vCPU and memory, AWS Identity and Access Management (IAM) roles, volume mount points, container properties, and environment variables for defining the job running process.
- Moreover, the AWS Batch executes your jobs as containerized applications running on Amazon ECS in which the Batch also enables you to specify dependencies between different jobs.
5. Support for GPU scheduling
- GPU scheduling provides access for specifying the number and type of accelerators your jobs need as job definition input variables in AWS Batch. Moreover, AWS Batch will scale up instances appropriate for your jobs depending sed on the needed number of GPUs and isolate the accelerators according to each job’s needs. This is that only the appropriate containers can access them.
6. Support for popular workflow engines
- AWS Batch can be combined with commercial and open-source workflow engines. Moreover, they can integrate with languages like Pegasus WMS, Luigi, Nextflow, Apache Airflow, and AWS Step Functions.
7. Integration with EC2 Launch Templates
- Now, AWS Batch has the support of EC2 Launch Templates. This allows for building customized templates for your compute resources and enabling Batch for scaling instances with those requirements.
- Further, you can define your EC2 Launch Template for adding storage volumes, specify network interfaces, or configure permissions, among other capabilities.
8. Flexible allocation strategies
AWS Batch allows customers to choose three methods for allocating compute resources. This planning allows customers for factoring in output as well as price while deciding the process of scaling instances for AWS Batch on their behalf.
- Firstly, Best Fit. In this, AWS Batch selects an instance type that fits bests for the job requirements with desiring for the lowest-cost instance type.
- Secondly, Best Fit Progressive. In this, the AWS Batch will select additional instance types that are large enough for meeting the needs of the jobs in the queue. This is done with keeping a preference for instance types having a reduced cost per unit vCPU.
- Lastly, Spot Capacity Optimized. In this, AWS Batch will select one or more instance types that are large enough for meeting the requirements of the jobs in the queue. This is done while keeping a preference for instance types that are slightly interrupted.
9. Integrated monitoring and logging
- AWS Batch shows key operational metrics for your batch jobs in the AWS Management Console. Here, you can view metrics related to compute capacity, including running, pending, and completed jobs.
10. Fine-grained access control
- AWS Batch uses IAM for controlling and monitoring the AWS resources that your jobs can access like Amazon DynamoDB tables. Further, using IAM, you can also specify policies for different users in your organization.

Use cases of Amazon Batch:
1. Financial services
For Financial Services organizations, AWS Batch helps in minimizing human error, increasing speed and accuracy, and reducing costs with automation.
- High-performance computing
AWS Batch helps organizations in automating the resourcing and scheduling of these jobs for saving costs and accelerating decision-making and go-to-market speeds.
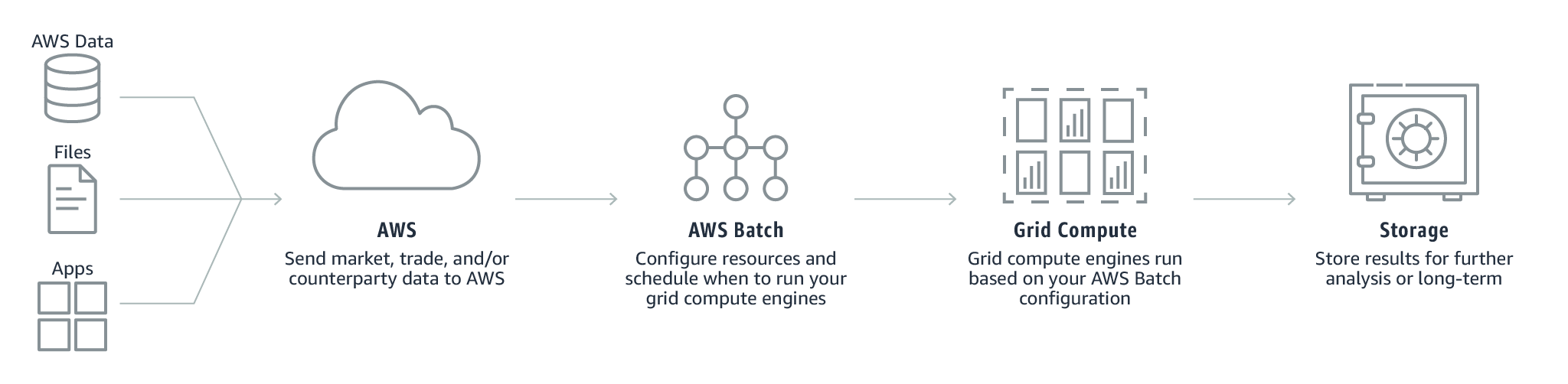
- Post-trade analytics
For this, AWS Batch allows the automation of these workloads so that you can understand the pertinent risk going into the next day’s trading cycle and making better decisions based on data.
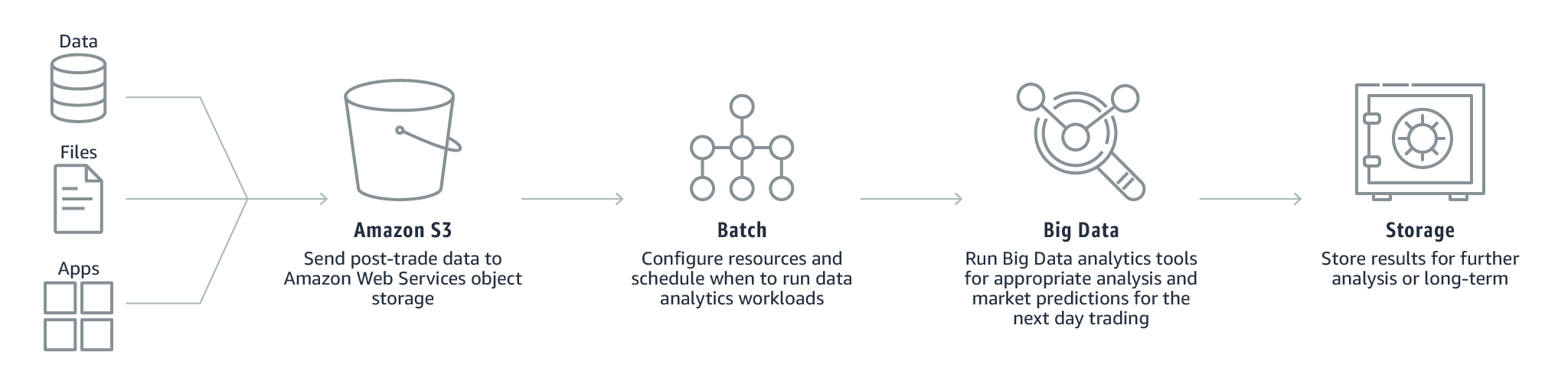
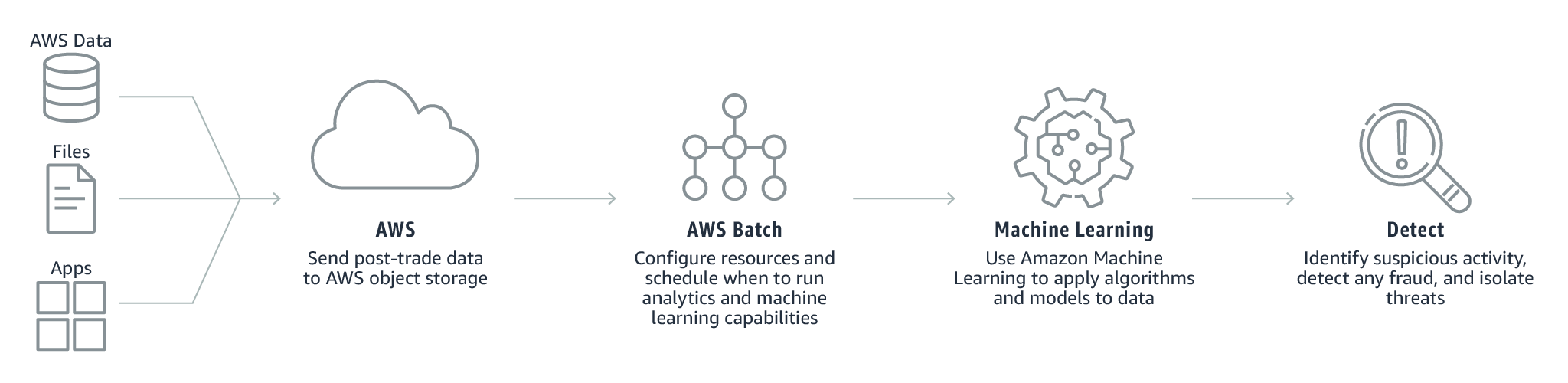
- Fraud surveillance
While using in conjunction with AWS Batch, organizations can automate the data processing or analysis needed for detecting irregular patterns in your data that could be an indicator of fraudulent activity like money laundering and payments fraud.
2. Life sciences
AWS Batch can be applied throughout your organization in applications like computational chemistry, clinical modeling, molecular dynamics, and genomic sequencing testing and analysis.
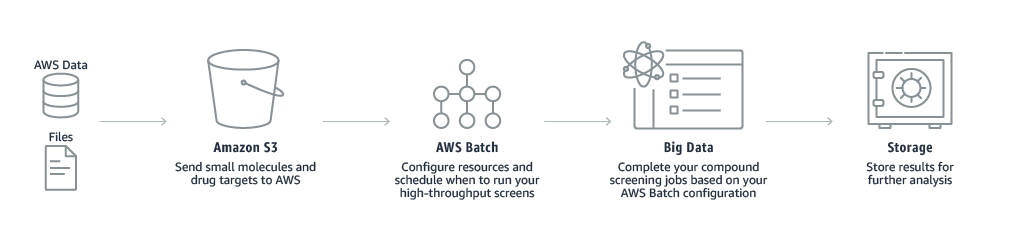
- Drug screening
AWS Batch allows research scientists involved in drug discovery to rapidly search libraries of small molecules for identifying those structures which are binding to a drug target. This helps in capturing better data for beginning drug design and have a deeper understanding of the role of a particular biochemical process.
- DNA sequencing
With AWS Batch helps customers in simplifying and automating the assembly of the raw DNA reads into a full genomic sequence. This is processed by comparing the multiple overlapping reads and the reference sequence.
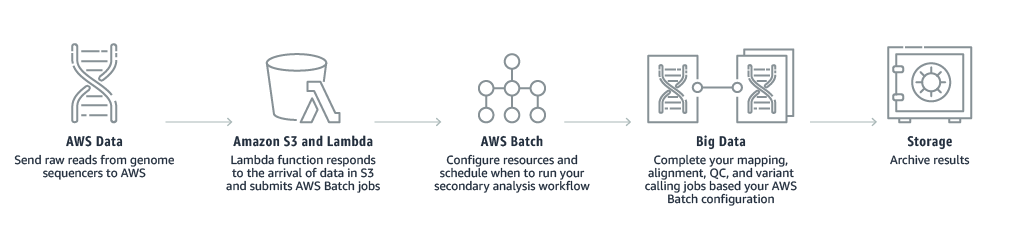
3. Digital media
AWS Batch helps in:
- Firstly, accelerating the content creation
- Secondly, dynamically scaling media packaging
- Lastly, automating asynchronous media supply chain workflows.
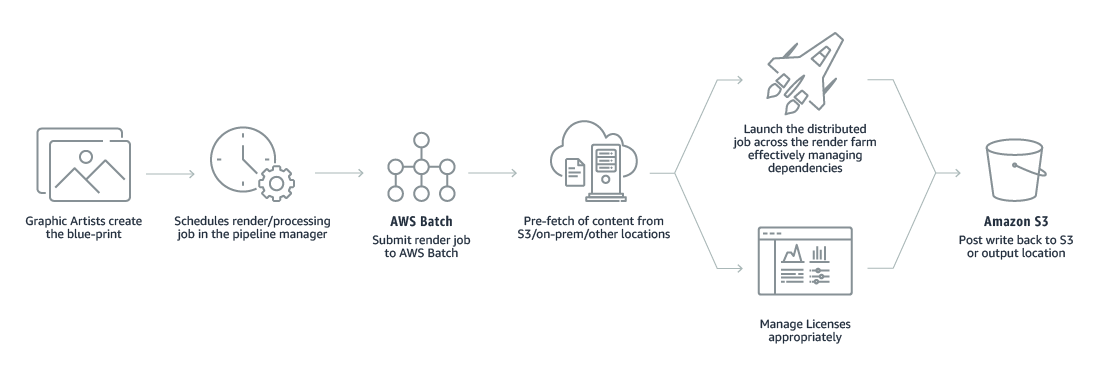
- Rendering
AWS Batch provides tools for automating content rendering workloads and reducing the need for human intervention to content producers and post-production houses. This is because of execution dependencies or resource scheduling.
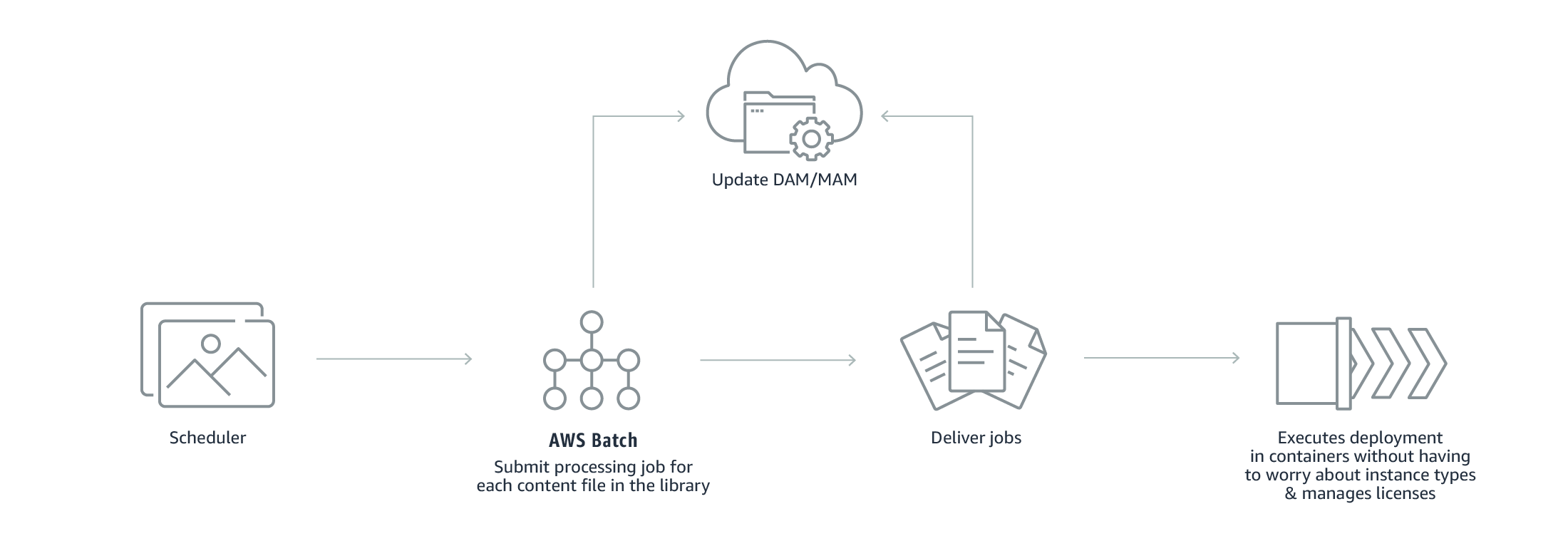
- Transcoding
AWS Batch accelerates batch and file-based transcoding workloads by automating workflows, overcoming resource bottlenecks, and lowering the number of manual processes by scheduling and monitoring the executing of asynchronous processes.
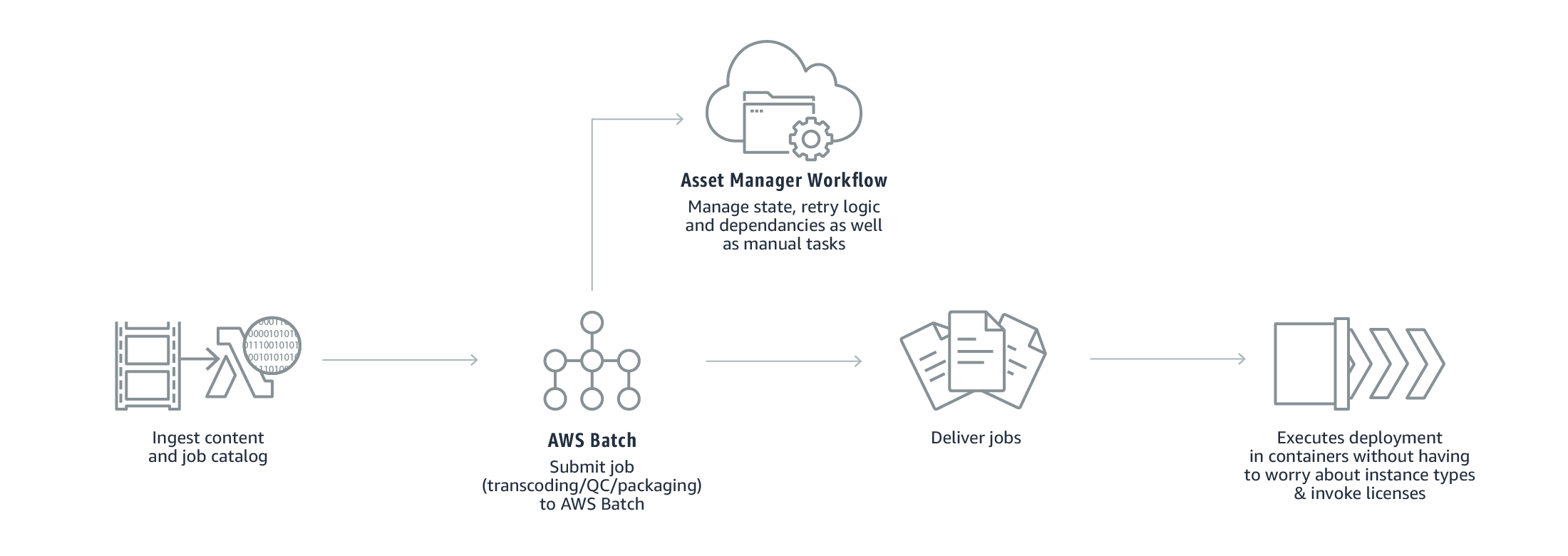
- Media supply chain
AWS Batch clarifies the complex media supply chain workflows by interrelating the performance of dependent jobs at different stages of processing. Moreover, it supports a common framework for controlling the content preparation for different contributors to the media supply chain.
Above we have covered the features, concepts, and use cases of AWS Batch. Now, let’s get started with the working of the batch beginning with defining a job.
Beginning with Amazon Batch
In this, we will start AWS Batch by creating a job definition, compute environment, and a job queue in the AWS Batch console.
Step 1: Define a Job
Here, you will define your job definition or move ahead for creating a compute environment and job queue without a job definition.
For configuring job options:
- Firstly, open the AWS Batch console first-run wizard.
- Secondly, for creating an AWS Batch job definition, computing environment, and job queue. After that, submit your job, select Using Amazon EC2. Further, select No job submission for only creating the compute environment and job queue without submitting a job.
- Lastly, if you select to create a job definition, then finish the next four parts of the first-run wizard. This includes Job run-time, Environment, Parameters, and Environment variables. After that, select Next. And, if you’re not creating a job definition, select Next and move on to Step 2.
For specifying job run time
- Firstly, if you’re creating a new job definition, for Job definition name, then, define a name for your job definition.
- Secondly, select the Docker image for using it for your job for the Container image. However, by default, images in the Docker Hub registry are available. Further, the parameter can be up to 255 characters in length which can contain uppercase and lowercase letters, numbers, hyphens (-), underscores (_), colons (:), periods (.), forward slashes (/), and number signs (#). And, the parameter plans to Image in the Create a container section of the Docker Remote API and the IMAGE parameter of docker run.
- Firstly, the images in Amazon ECR repositories use the full registry/repository:tag naming convention.
- Secondly, images in official repositories on Docker Hub use a single name.
- Thirdly, images in other repositories on Docker Hub are qualified with an organization name.
- Lastly, images in other online repositories are qualified further by a domain name.
For specifying resources for your environment:
- Firstly, define the command for passing to the container. This parameter plans to Cmd in the Create a container section of the Docker Remote API and the COMMAND parameter to docker run.
- Secondly, define the number of vCPUs for reserving for the container.
- Thirdly, define the hard limit (in MiB) of memory for presenting to the job’s container. However, if your container attempts to exceed the memory then, the container is stopped.
- Lastly, define the maximum number of times for attempting your job.
Step 2: Configuring the Compute Environment and Job Queue
A computing environment is a way to reference your compute resources. That is to say, the settings and constraints that tell AWS Batch how instances should be configured and automatically launched. However, you submit your jobs to a job queue that stores jobs until the AWS Batch scheduler runs the job on a compute resource within your compute environment.
For configuring your compute environment type
- Firstly, define a unique name for your compute environment.
- Secondly, select to create a new role or use an existing role that allows the AWS Batch service for making calls to the required AWS APIs on your behalf.
- Thirdly, select to create a new role or use an existing role that allows the Amazon ECS container instances that are created for your compute environment for making calls to the needed AWS APIs on your behalf.
For configuring your instances
- Firstly, select On-Demand for launching Amazon EC2 On-Demand instances or Spot for using Amazon EC2 Spot Instances.
- However, if you select to use Amazon EC2 Spot Instances:
- Firstly, select the maximum percentage that a Spot Instance price must be compared with the On-Demand price for that instance type before instances are launched.
- Secondly, select to create a new role or use an existing Amazon EC2 Spot Fleet IAM role for applying to your Spot compute environment.
- Then, select the Amazon EC2 instance types that can be launched. Here, you can define instance families for launching any instance type inside those families.
- However, if you select to use Amazon EC2 Spot Instances:
- After that, select the minimum number of EC2 vCPUs that your compute environment should maintain anyhow of job queue demand.
- Next, select the number of EC2 vCPUs that your compute environment should launch with. As your job queue request increases, AWS Batch can increase the desired number of vCPUs in your compute environment and add EC2 instances, up to the maximum vCPUs. And when the demand decreases, AWS Batch can decrease the desired number of vCPUs in your compute environment and remove instances, down to the minimum vCPUs.
- Lastly, select the maximum number of EC2 vCPUs that your compute environment can scale out anyhow of job queue demand.
For setting up your job queue:
- Firstly, submit your jobs to a job queue that keeps the jobs. This is done until the AWS Batch scheduler starts running the job on a compute resource inside compute environment.
- Then, select a unique name for your job queue.
– Amazon Batch pricing
You must know that there is no additional charge for AWS Batch. In other words, you only have to pay for AWS resources that you create for storing and running your application. This can be which can be EC2 instances, AWS Lambda functions, or AWS Fargate. Moreover, you can use your Reserved Instances, Savings Plan, EC2 Spot Instances, and Fargate with AWS Batch by defining your compute-type needs while setting up your AWS Batch compute environments.
Final Words
By introducing Batch services, AWS provided the best solution for handling job execution and computing resource management in order to have more focus on developing applications or analyzing results. This service is widely used by organizations for running or moving batch workloads to AWS. However, with having no additional charge for Amazon Batch, you can pay only for AWS Resources you will create for storing and running your batch jobs. So, if you have an interest in learning and understanding about AWS batch, then begin using the AWS documentation guide and start building & running your first batch job with AWS Batch.
Enhance your AWS Batch skills by clearing the AWS SysOps Administrator Associate (SOA-C02) exam.